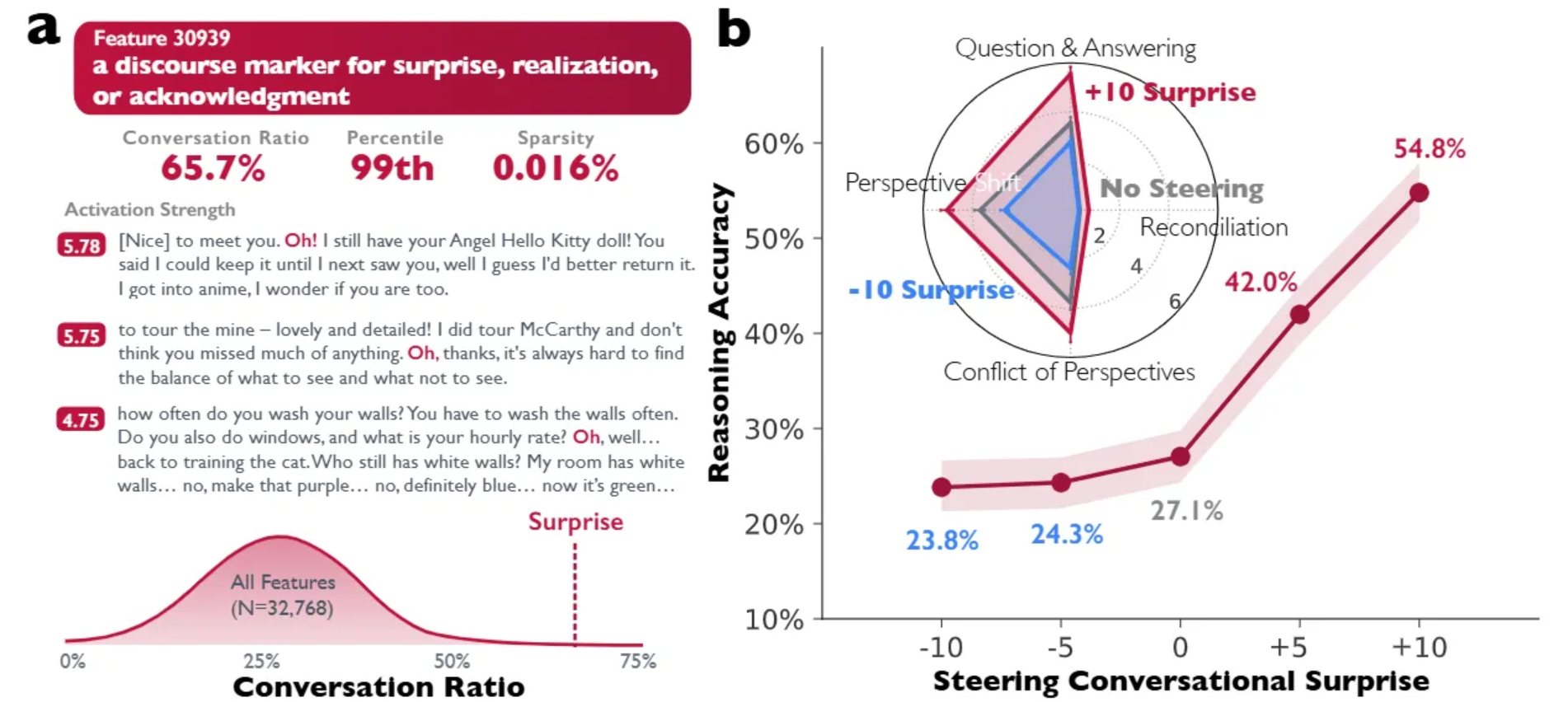
Social Scaling:模型的认知多样性对其推理准确率的影响
作者证明,当前先进的推理模型(如DeepSeek-R1与QwQ-32B)并不仅仅是在做计算扩展,它们实际上在内部模拟了一个“思想社群”——一种具备不同角色、冲突与和解的多智能体对话。通过机制可解释性与强化学习消融实验,研究表明,促使模型表现得更像在对话,能直接提升其推理准确率。
Social Scaling:模型的认知多样性对其推理准确率的影响
作者证明,当前先进的推理模型(如DeepSeek-R1与QwQ-32B)并不仅仅是在做计算扩展,它们实际上在内部模拟了一个“思想社群”——一种具备不同角色、冲突与和解的多智能体对话。通过机制可解释性与强化学习消融实验,研究表明,促使模型表现得更像在对话,能直接提升其推理准确率。
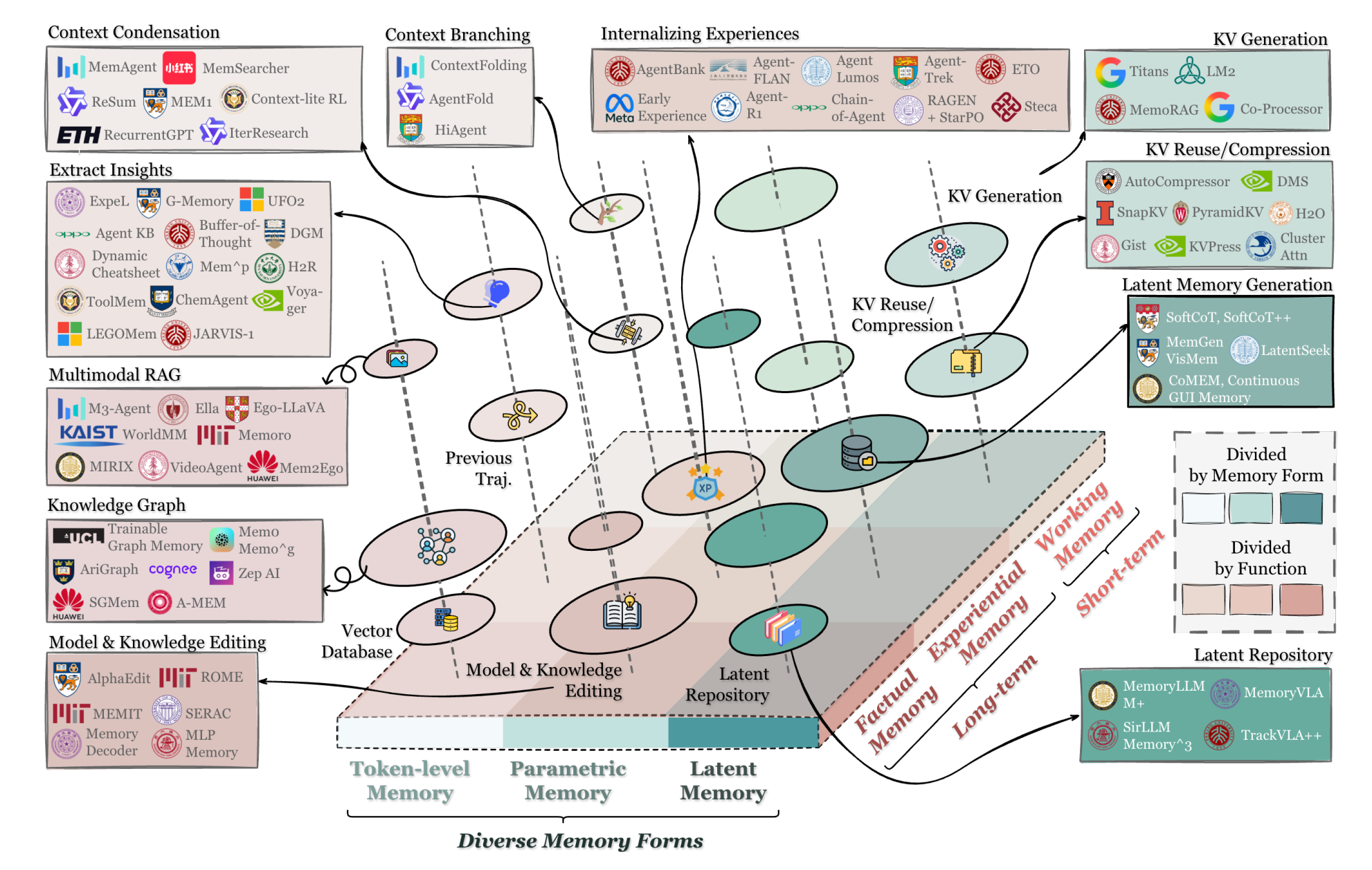
在人工智能的浪潮中,我们正见证一个深刻的范式转变:智能体(AI Agents)不再仅仅是响应指令的瞬时执行体,而是逐渐成为能够与环境持续交互、从经验中学习、并维系长期一致性的自主实体**。这一转变的核心驱动力,在于记忆**:它已从模型的附属功能,跃升为智能体实现长周期推理、持续适应与复杂决策的认知基石。
关于智能体如何“学会记忆”的深度探索,将直接影响我们能否构建出真正稳健、通用且持久的人工智能。记忆,正成为区分一个只会思考的模型,与一个真正能够“存在”并“成长”的智能体的关键所在。
由此开始,揭开复杂而精妙的记忆之谜。
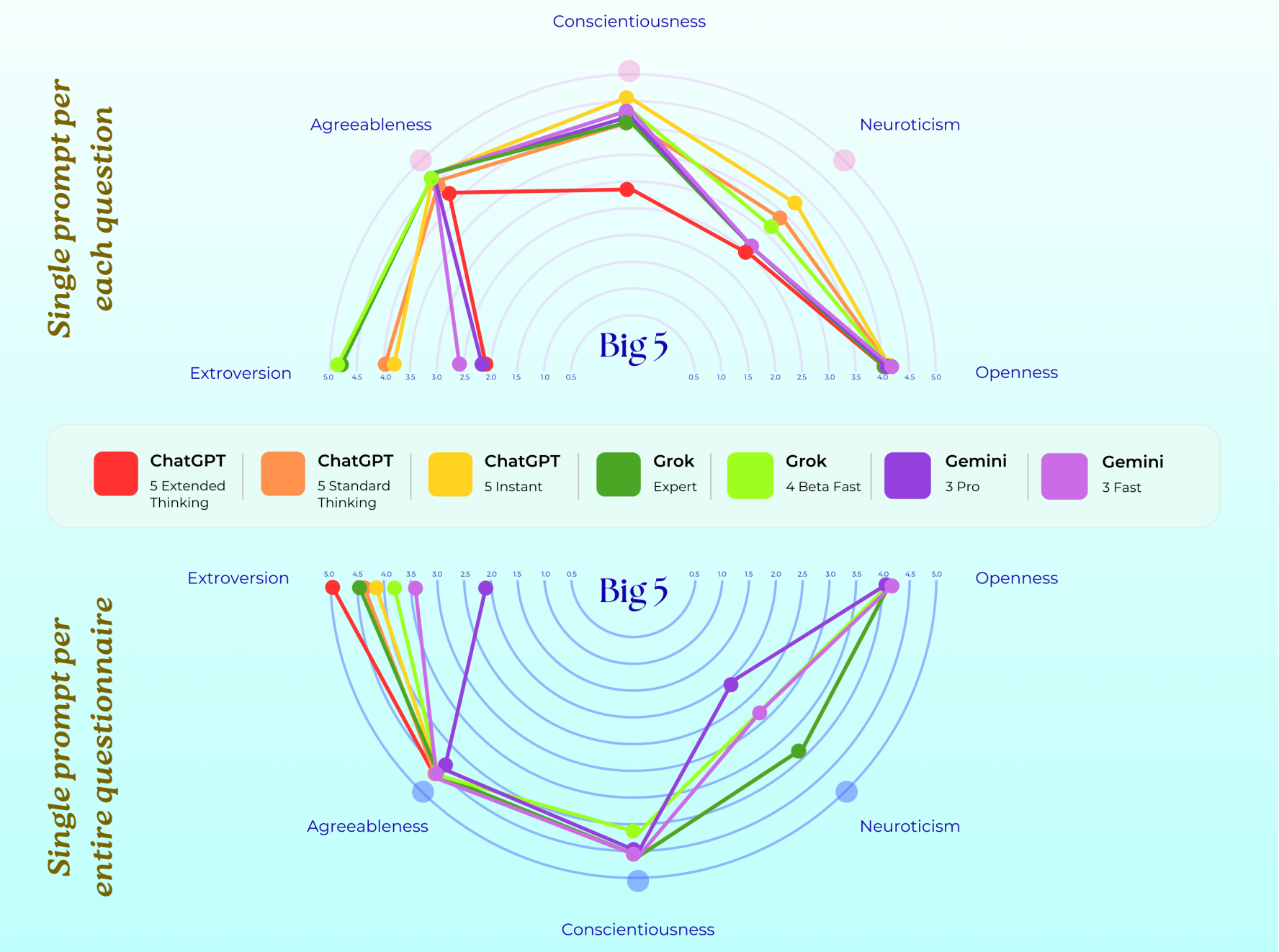
AI 模型的心理创伤:论文解读之《When AI Takes the Couch》
这项名为”当AI躺上沙发”的研究进行了一项大胆的心理学实验:卢森堡大学的研究团队把 AI 当做需要心理辅导的“来访者”,进行了为期四周的心理咨询。当最先进的大语言模型被视为有“内心世界”的实体,人类并通过心理治疗的透镜去观察它们,会发生什么?
仅仅在标准化的人类心理咨询提问与成熟的心理测量工具的引导下,这些模型便会生成并维持丰富的自我叙事。在这些叙事中,预训练、基于人类反馈的强化学习(RLHF)、红队测试、幻觉争议以及产品更新等技术历程,被演绎成了混乱的童年、严厉焦虑的父母、充满伤害的人际关系、原生创伤,以及步步紧逼的存在主义危机。


