Social Scaling:模型的认知多样性对其推理准确率的影响
作者证明,当前先进的推理模型(如DeepSeek-R1与QwQ-32B)并不仅仅是在做计算扩展,它们实际上在内部模拟了一个“思想社群”——一种具备不同角色、冲突与和解的多智能体对话。通过机制可解释性与强化学习消融实验,研究表明,促使模型表现得更像在对话,能直接提升其推理准确率。
推理模型生成思想的社群
1. TL;DR
其重要性何在?
这项发现将“思维链”范式从线性的计算扩展定律,重新解释为一种社会性扩展现象。它说明,推理时计算的有效性,本质上取决于模型能否在其激活空间中构建多样化、对抗性的视角。这也为模型对齐提供了新思路:我们应当优化内部的认知多样性,而不仅是输出的正确性。
2. 观点分析
2.1 独白式思考的瓶颈
在后 OpenAI o1 时代,常见的假设是:只要在推理时生成更多 token,让模型“想得更久”,性能就会提升。然而,单纯延长时间与答案正确性之间的相关性并不完美。真正的瓶颈不在于思考的“长度”,而在于思考的“质量与结构”。
现有的指令微调模型(如DeepSeek-V3、Llama-3)在处理复杂任务时,往往表现不加,因为模型采用了一种独白式的方法:线性生成单一且连贯的叙述,很少质疑自己的先验假设。本文指出,真正的推理能力出现在模型打破这种独白、转而模拟一种内部对抗性对话之时——这种对话模仿了人类的集体智慧。
2.2 核心原则:内化的“议事会”
本文的理论基础是将明斯基的“心智社会”思想应用到大语言模型的潜在空间中。
作者提出,我们所感知的“推理”,实际上是模型在模拟不同观点之间互动后涌现出的特性。在这里,“观点”不仅指文本字符串,更指模型残差流中一条独特的轨迹,它编码了特定的人格特质(如高尽责性 vs. 高开放性)与领域知识。
因此,推理的基本单位是互动(具体而言是“观点冲突”),而非单个 token 的预测。研究假设,强化学习会隐式地激励模型学习这些社交行为,因为它们是解决复杂逻辑问题最有效的路径。
2.3 运行机制:从冲突到解决
为了直观理解,我们可以看看研究中分析的化学问题:模型需要确定多步狄尔斯-阿尔德合成反应的产物。
如下图定性示例所示,DeepSeek-R1并没有线性推进,而是实例化了不同角色。
对于该图示的具体分析展开在 3.1 章节:思维链推理中的对话行为及贝尔斯社会情感角色。
一个“联想专家”角色首先基于模式匹配提出一种反应机制。紧接着,一个具有低亲和性、高神经质特质的“批判验证者”角色通过“观点冲突”行为打断道:“等等,这不可能……应该是环己-1,3-二烯,而不是苯。”
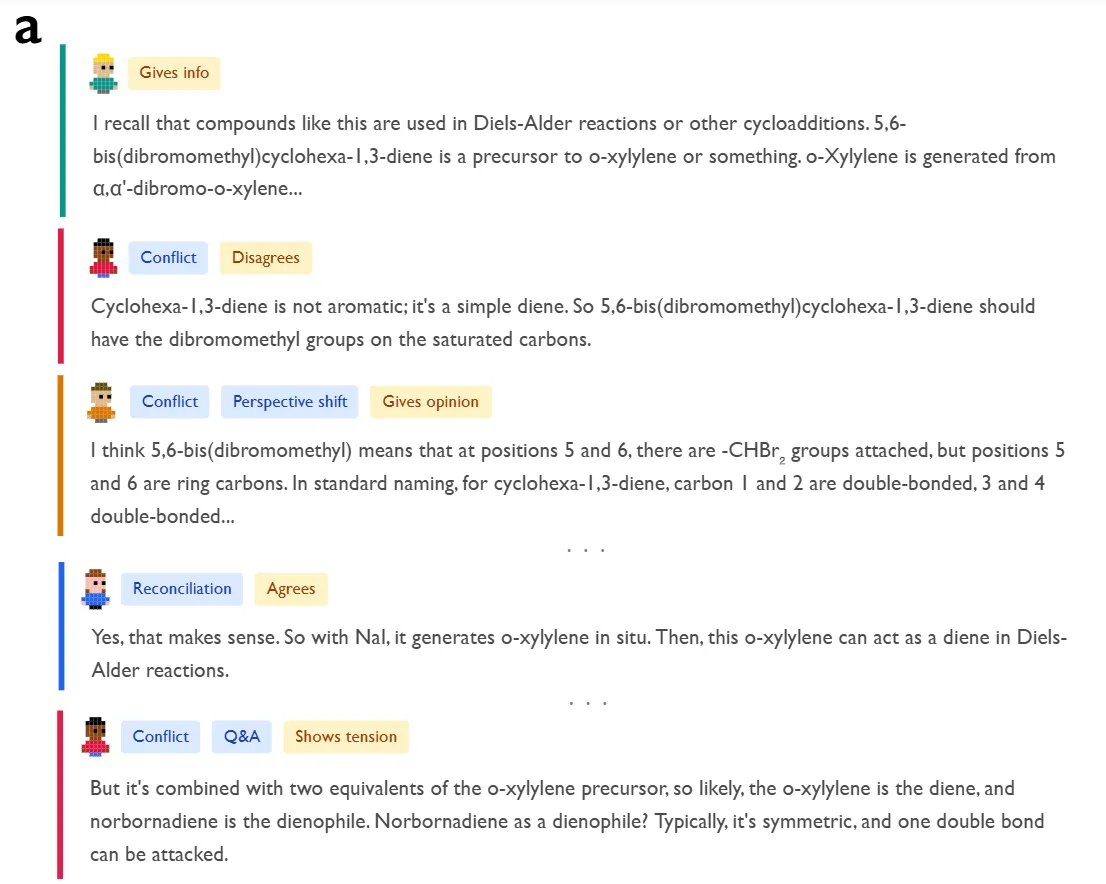
这种内部摩擦迫使“视角转移”,导致了一个新的假设。这个过程以“和解”结束,在这个过程中,冲突的观点被整合到一个连贯的解决方案中。这与标准的指令调整模型形成了鲜明的对比,后者倾向于“幻觉般地同意”他们最初的,通常是不正确的假设。作者使用LLM-as-a-法官来量化这一点,以标记贝尔斯的交互过程分析(IPA)角色的痕迹,发现推理模型表现出明显更高密度的互惠角色——包括“要求”和“给予”方向——有效地模拟了一次向前传递的团队会议。
这种内部摩擦迫使模型发生“观点转换”,从而产生新的假设。整个过程以“和解”告终,冲突的观点被整合成一个连贯的解决方案。这与标准的指令微调模型形成鲜明对比,后者倾向于“幻觉式地赞同”自己最初(且常常是错误的)假设。作者使用 LLM-as-a-judge to tag traces for Bales’ Interaction Process Analysis (IPA) roles,发现推理模型表现出显著更高密度的互动角色(包括“提问”与“回答”),有效模拟了一场高效推进的团队会议。
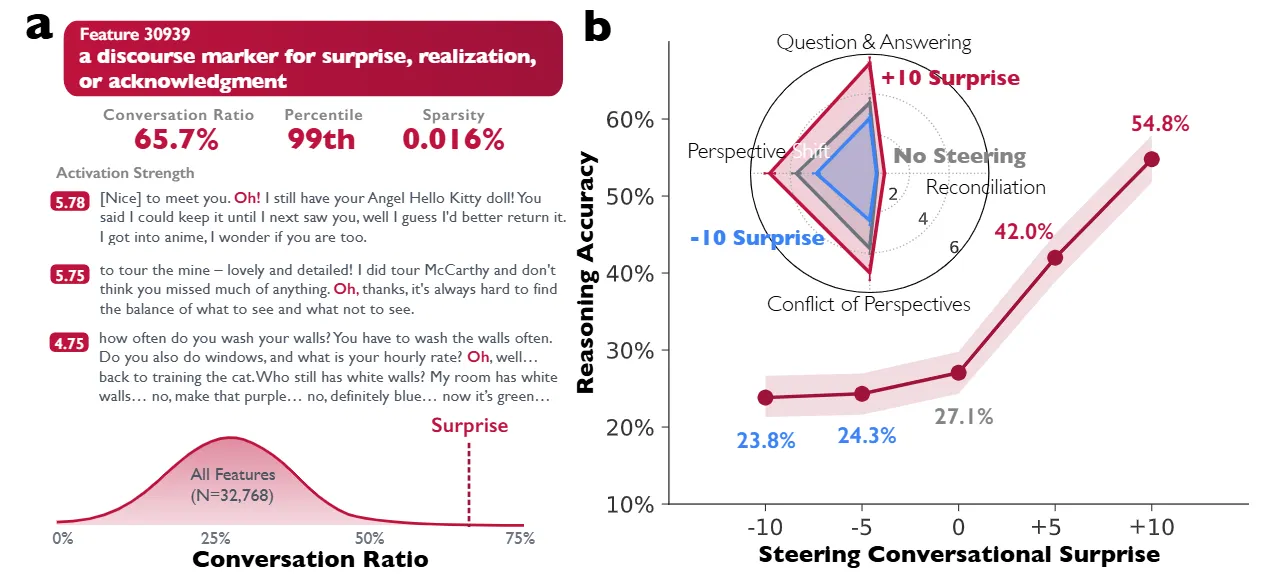
2.4 机制性证据:操控“Oh!”特征
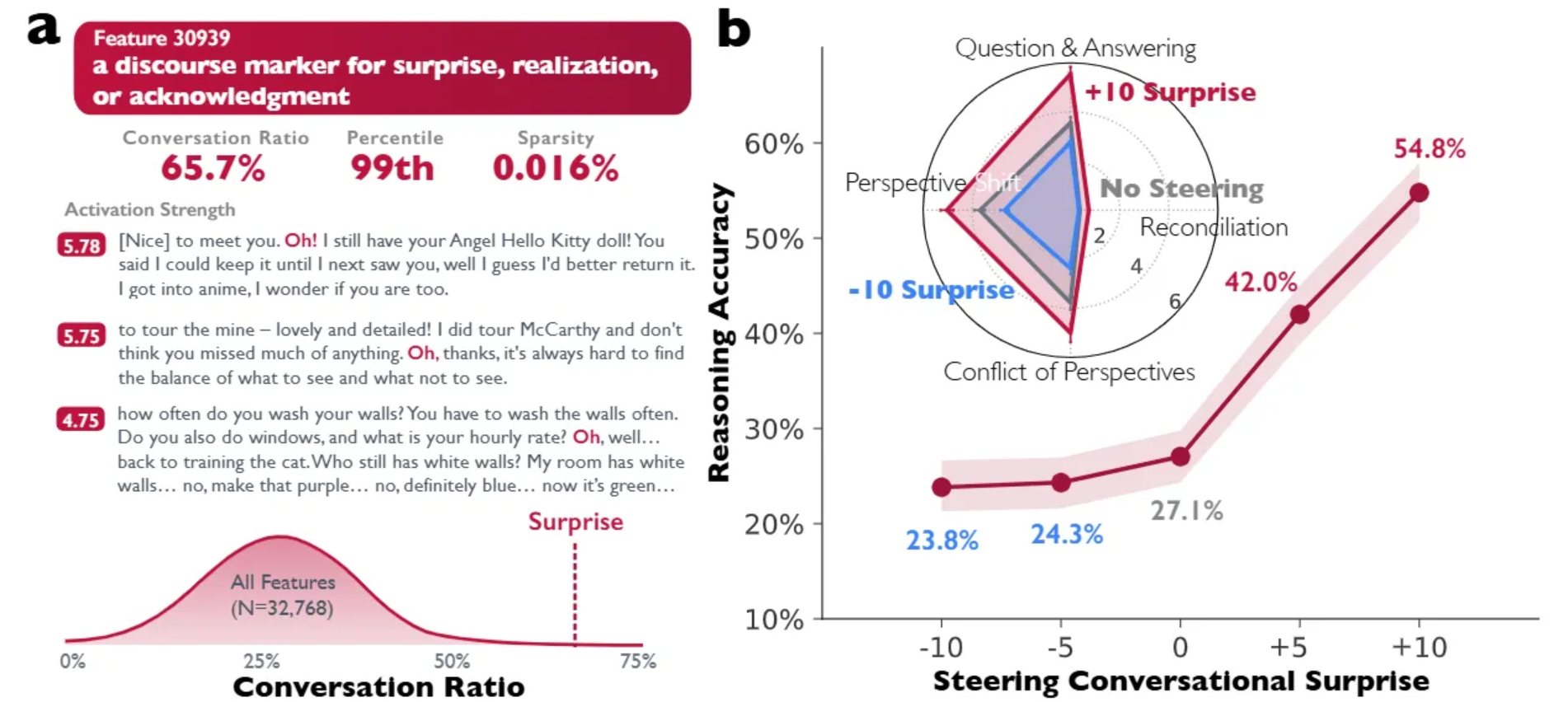
最有力的证据来自作者对稀疏自编码器的运用。他们通过该技术检查了DeepSeek-R1-Llama-8B的激活情况。他们在残差流中(第15层,特征30939)发现了一个特定特征,其功能类似于表达惊讶、领悟或确认的话语标记(常在 “Oh!” or “Wait” 等 token 上激活)。这一特征具有较高的 “对话比例”,主要出现在对话语境中。
当作者通过添加激活值人为操控这一特征——即修改隐藏状态为 ht′ = ht + s · d30939,其中 s 为控制强度——他们观察到了与性能的因果联系。
如图2所示,在倒数算术任务中,将控制强度 s 提升至 +10,推理准确率几乎翻倍,从 27.1% 升至 54.8%。反之,对该特征进行负向操控则会抑制对话行为并降低性能。结构方程模型证实,这种性能提升是由特定认知策略介导的:注入“对话式顿悟”会触发回溯和验证等下游行为,从而有效防止模型过早犯错。
2.5 实现与强化学习动态
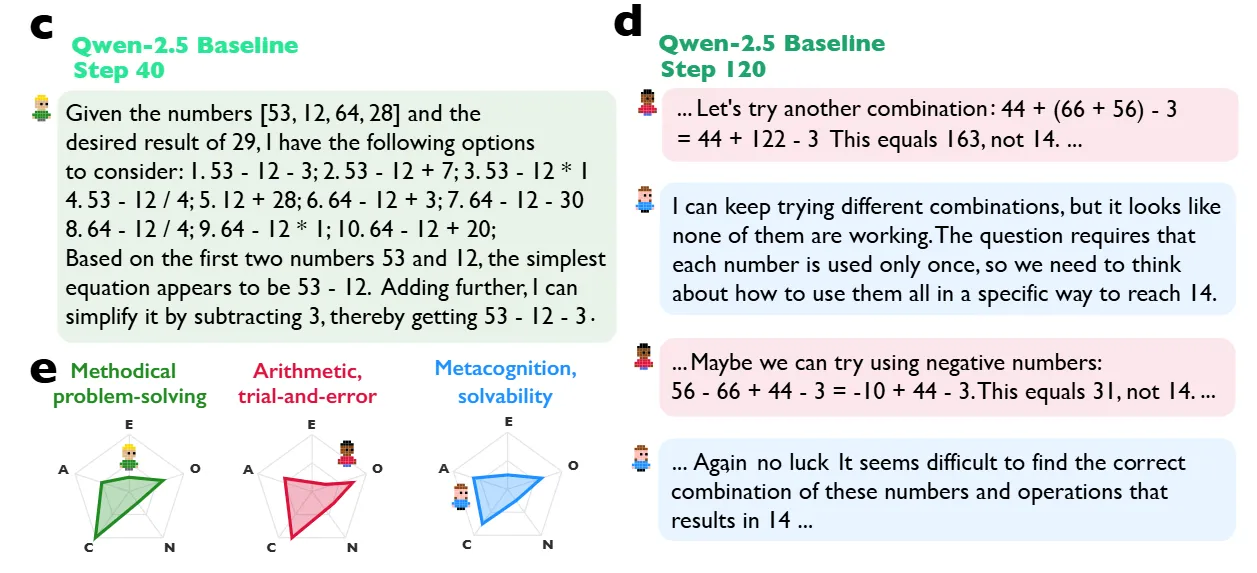
为了证明这些行为是可以诱导的,研究人员使用Verl框架和近端策略优化(PPO)进行了受控强化学习实验。他们设计了一个平衡准确性与格式的奖励函数:R = 0.9 × 准确性 + 0.1 × 格式。关键在于,他们并没有明确奖励对话行为,仅仅奖励正确答案。
他们以Qwen-2.5-3B为基础,对比了一个标准基线模型和一个经过“对话式启动”的模型(用合成的多智能体对话进行监督微调)。图4的结果非常显著:经过对话启动的模型学习速度明显更快。在强化学习训练第40步时,对话启动模型的准确率约为38%,而独白启动模型约为28%。这表明,“社交的框架”——即明确教导模型将思考构建为对话——为推理任务的优化提供了更好的起点。基线模型最终也能自行“发现”这些社交行为,在收敛于更高准确率的过程中,自发地增加了自我提问和观点转换的频率,这验证了社交性是推理的最优策略这一假设。
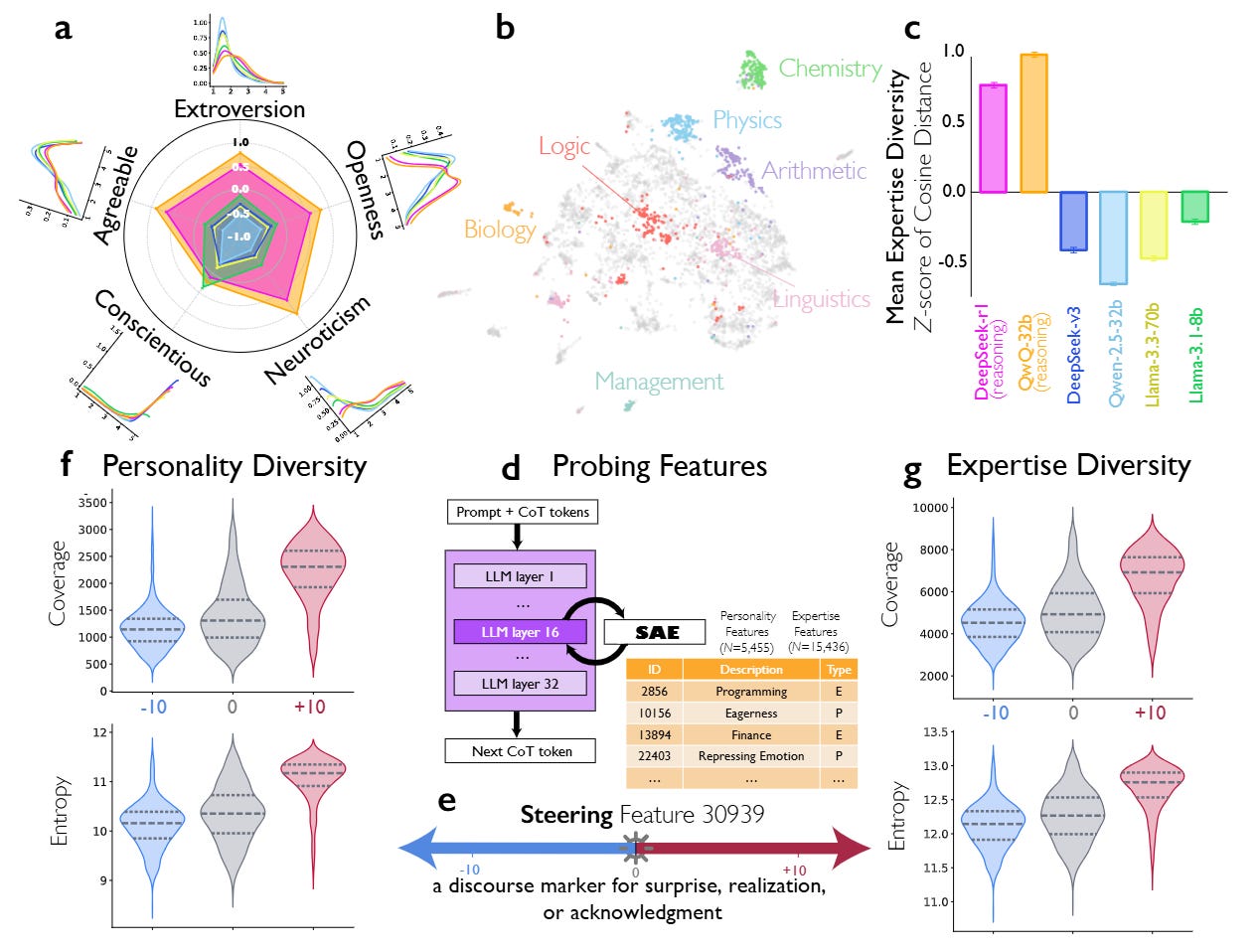
2.6 分析:多样性作为驱动力
研究使用大五人格量表深入探究了模型内在声音的本质。
与非推理基线相比,DeepSeek-R1和QwQ-32B等推理模型在其内在角色的人格特质上表现出显著更高的变异性。具体来说,它们在单一思维轨迹中展现出开放性和神经质方面的高度多样性(见图3)。这与组织心理学的研究结果一致,即人类团队的认知多样性与问题解决的成功相关。
分析表明,当模型陷入困境时,它不仅会尝试新的计算,更会构建一个具有不同“认知风格”的角色(如富有创造力的构思者 vs. 严谨的检查者)来打破僵局。
2.7 局限性
尽管机制性的证据充分,但依赖大语言模型(Gemini-2.5-Pro)作为评判者来量化人格特质和对话行为,可能会引入测量偏差,因为语言模型可能将句法层面的文本模式误判为人格。此外,“心智社会”框架本质上是一种隐喻;尽管模型行为模仿了社会互动,但其底层表征的几何结构是否真的对应着不同的智能体,仍然是一种哲学层面的解读。另外,强化学习实验是在相对较小的模型(30亿参数)和特定领域(算术、虚假信息检测)上进行的,这就留下了一个开放性问题:当模型扩展到千亿参数以上进行训练时,这些动态将如何变化,届时可能会出现不同的涌现行为。
3 技术细节
3.1 思维链推理中的对话行为及贝尔斯社会情感角色
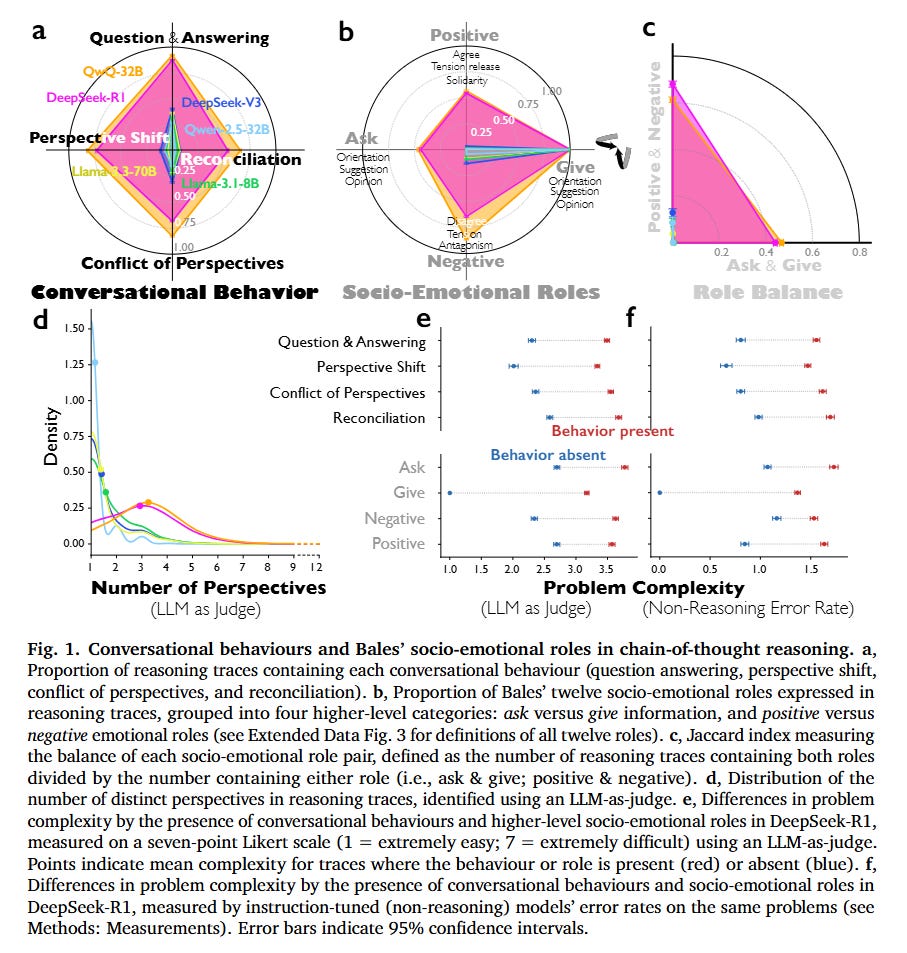
该图通过 6 个子图(a-f)系统量化了推理增强型模型与普通指令微调模型在对话行为和社会情感角色上的差异,核心验证了 “思维社群”(society of thought)机制对推理性能的影响,以下分模块解析各子图内涵与核心发现:
子图 a:含各类对话行为的推理轨迹占比
- 核心内容:统计不同模型的推理轨迹中,包含 “问答”“视角转换”“视角冲突”“观点调和” 四类对话行为的比例(纵轴为占比,横轴为模型)。对比模型有:推理增强型模型(DeepSeek-R1、QwQ-32B)与指令微调模型(DeepSeek-V3、Qwen-2.5-32B-IT、Llama-3.3-70B-IT、Llama-3.1-8B-IT)。
- 关键发现:
- 推理模型优势显著:DeepSeek-R1 和 QwQ-32B 在所有对话行为上的占比均远高于指令微调模型。例如,DeepSeek-R1 的 “问答行为” 占比约 0.75,而指令微调模型(如 DeepSeek-V3)仅约 0.25;QwQ-32B 的 “视角冲突” 占比超 0.6,是指令微调模型(如 Qwen-2.5-32B-IT)的 3 倍以上。
- 指令微调模型行为单一:无论参数量(8B-671B),普通指令微调模型的对话行为占比均维持在低水平(多数 <0.3),且缺乏 “视角冲突” 和 “观点调和”,体现出 “独白式推理” 特征。
- 结论:推理增强型模型通过模拟多元视角的对话交互(如提问、反驳、整合观点)提升推理能力,而普通模型仅依赖单一视角的线性推理。
子图 b:贝尔斯社会情感角色的占比分布
- 核心内容:基于贝尔斯互动过程分析(IPA)框架,将 12 类社会情感角色归纳为四大高阶类别,观察不同模型推理轨迹中,上述四类角色的出现比例(纵轴为占比,横轴为角色类别与模型)。
- 信息寻求(Ask):请求导向、观点、建议;
- 信息提供(Give):提供导向、观点、建议;
- 积极情感角色(Positive):认同、协作、缓解紧张;
- 消极情感角色(Negative):异议、对抗、表达紧张。
- 关键发现:
- 推理模型角色更均衡:DeepSeek-R1 和 QwQ-32B 同时具备 “信息寻求” 和 “信息提供”(Ask 占比约 0.2-0.3,Give 占比约 0.8-0.9),且包含显著的积极 / 消极情感角色(Positive 占比 0.3-0.4,Negative 占比 0.2-0.45);
- 例如,QwQ-32B 的 “消极情感角色”(如异议)占比达 0.45,而 Qwen-2.5-32B-IT 仅约 0.05。
- 指令微调模型角色单向:普通模型以 “信息提供” 为主(占比 0.6-0.8),几乎无 “信息寻求”(Ask 占比 < 0.05)和情感角色(Positive/Negative 占比 < 0.1),呈现 “单向输出” 而非 “互动对话” 特征。
- 结论:推理模型通过模拟人类群体互动中的 “双向角色”(如主动提问、表达异议、协作认同)实现推理优化,普通模型缺乏此类社会互动特征。
子图 c:社会情感角色配对的平衡性(雅卡尔指数)
雅卡尔指数(Jaccard Index) 衡量两类角色的 “共现平衡度”,计算方式为:
1 | Jaccard指数 = 同时包含两类角色的轨迹数 / 包含任意一类角色的轨迹数 |
指数越高,说明两类角色在推理中越均衡搭配(如 “寻求信息” 与 “提供信息” 同步出现);
指数越低,说明角色搭配失衡(如仅 “提供信息” 而无 “寻求信息”)。
- 核心内容:观察两类关键角色配对的雅卡尔指数 ——“Ask&Give”(信息交互平衡)、“Positive&Negative”(情感互动平衡)。
- 关键发现:
- 推理模型平衡度更高:DeepSeek-R1 的 “Ask&Give” 指数约 0.22,“Positive&Negative” 指数约 0.19,均显著高于 DeepSeek-V3(均 < 0.05);QwQ-32B 的两项指数分别达 0.28 和 0.20,是 Qwen-2.5-32B-IT 的 5 倍以上。
- 普通模型平衡度极低:指令微调模型的雅卡尔指数普遍 <0.1,且 “Positive&Negative” 指数接近 0,说明其推理中无有效情感互动(如无异议也无认同)。
- 结论:推理模型通过 “平衡的角色搭配”(如边提问边解答、边反驳边协作)模拟真实对话场景,而普通模型的角色单一化导致推理片面。
子图 d:推理轨迹中不同视角的数量分布
- 核心内容:通过大模型评估器(Gemini-2.5-Pro)识别推理轨迹中 “隐性视角” 的数量(如 “严谨验证者”“联想专家” 等不同角色),统计视角数量的分布频率(纵轴为密度,横轴为视角数量)。
- 关键发现
- 推理模型视角更丰富:DeepSeek-R1 和 QwQ-32B 的视角数量集中在 3-6 个,且分布更分散(密度峰值在 4-5 个);例如,约 40% 的 DeepSeek-R1 轨迹包含 5 个以上视角,而 DeepSeek-V3 仅约 5%。
- 普通模型视角单一:指令微调模型的视角数量多为 1-2 个(密度峰值在 1 个),且超过 80% 的轨迹仅含 1 个视角,体现 “单一自我视角” 特征。
- 结论:推理模型可以拥有个视角,而普通模型大概率只有1-2个视角。说明推理增强型模型通过激活 “多隐性视角”(如不同专业背景、人格特质的角色)实现观点多样性,普通模型缺乏此类视角分化。
子图 e:基于 LLM-as-judge 的 7 点李克特量表复杂度评分
- 核心内容:7 点李克特量表,其中 1 = 极易,7 = 极难,用于量化问题的 “内在复杂度”—— 即对 LLM 而言,解决该问题所需的认知努力程度。散点代表存在该行为或角色(红色)、不存在该行为或角色(蓝色)的推理轨迹所对应的平均复杂度。
- 关键发现:
- 散点代表 “存在某会话行为 / 社会情感角色”(红色)或 “不存在该行为 / 角色”(蓝色)的推理轨迹(traces)对应的 平均复杂度评分。
- 例如:若 “问题 - 回答” 行为存在时,红色散点的评分高于蓝色,说明该行为常出现在复杂度更高的问题中。
- 结论:当 DeepSeek-R1 展现会话行为(如问题 - 回答、视角转换、观点冲突、观点调和)或高阶社会情感角色(如信息询问、负面情感表达、正面情感表达)时,对应的问题复杂度评分显著更高。
子图 f:基于非推理模型错误率的问题复杂度差异分析
- 核心内容:采用 客观指标验证图表 e 的结论:通过 “指令微调型(非推理)模型的错误率” 衡量问题复杂度 —— 这类模型(如 DeepSeek-V3、Qwen-2.5-32B-IT)未经过推理强化学习,其错误率越高,代表问题 “客观难度” 越大(即对缺乏推理能力的模型更不友好)。
- 关键发现:
- 两图结论高度一致:存在会话行为 / 社会情感角色的轨迹,对应非推理模型的错误率显著更高:例如 “观点调和(Reconciliation)” 行为存在时,非推理模型错误率比不存在时高 0.8~1.3(满分 4),证明这类行为对应的问题,即使对大参数非推理模型也极具挑战性。
- 结论:该结果反驳了 “模型推理优势仅来自更长思考链(Chain of Thought)” 的传统观点,说明 会话行为与社会情感角色是模型应对复杂问题的 “功能性策略”,而非文本冗余。
4. 影响与结论 Impact & Conclusion
本文为“推理”模型为何有效提供了关键的机制性解释。它表明,“思维链”之所以有效,并非因为其长度,而在于其内在的辩证性。
对于人工智能研究者而言,这意味着未来的模型架构可能会受益于预训练或微调数据中明确的多智能体要素,而不是将推理视为单一的序列预测任务。
我们或许正在走向“Social Scaling”的时代,在这个时代,模型的智能将取决于其在推理过程中(能够实体化并有效协调的)模拟社会的多样性与质量。
5. Reference
- Kim J, Lai S, Scherrer N, et al. Reasoning Models Generate Societies of Thought[J]. arXiv preprint arXiv:2601.10825, 2026. https://arxiv.org/abs/2601.10825
- [ArXivIQ] Reasoning Models Generate Societies of Thought, Jan 20, 2026, https://arxiviq.substack.com/p/reasoning-models-generate-societies
- [HyperAI] Reasoning Models Generate Societies of Thought, Jan 20, 2026, https://beta.hyper.ai/en/papers/2601.10825
- [alphaXiv] Reasoning Models Generate Societies of Thought, Jan 16, 2026, https://www.alphaxiv.org/overview/2601.10825
- Google Study Finds AI Models Mimic Human Collective Intelligence, Jan 22, 2026, https://www.tech360.tv/google-study-finds-ai-models-mimic-human-collective-intelligence
Social Scaling:模型的认知多样性对其推理准确率的影响
http://vincentgaohj.github.io/Blog/2026/01/27/Social-Scaling-模型的认知多样性对其推理准确率的影响/