TPU 与 GPU 的未来竞争格局态势
本文基于 SemiAnalysis 2025 年 11 月报告,聚焦谷歌 TPU 的技术升级、商业化进展及产业链布局,分析其对 AI 硬件竞争格局的影响。核心围绕 TPU v7 的性能突破(逼近英伟达 GPU)、成本优势(TCO 更低、利润率更高)、ICI 架构的扩展性创新,结合谷歌与 Anthropic、WULF 等的关键交易,阐述 TPU 从内部使用走向全面商业化的转变。同时梳理了 TPU 产业链生态,对比英伟达 GPU 生态,凸显谷歌在 AI 算力硬件领域的差异化竞争力,预示其将成为英伟达在 AI 训练 / 推理硬件市场的核心竞争对手。
核心观点
【商业逻辑】
一、短期内,谷歌 TPU 外售的商业化落地为云服务提供商(CSP)提供了潜在 的替代选项,强化了 CSP 对英伟达的议价能力。
- 据 SemiAnalysis 报,OpenAI 以转向 TPU 采购为谈判条件,成功从英伟达获得约 30%的 GPU 采购折扣。 但当前冲击主要集中在议价环节,尚未形成实质性的份额替代。
二、除了 TPU 惯有的高性价比、扩展性、灵活性优势外,谷歌着重优化了 TPU 生态,大幅提升了外部可用性。
- 谷歌 2025 年加速优化了TPU 生态,原生支持 PyTorch,并在 vLLM 的 TPU 支持上进行大规模工程投入,接入开放推理生态,大幅提升 TPU 的外部可用性;
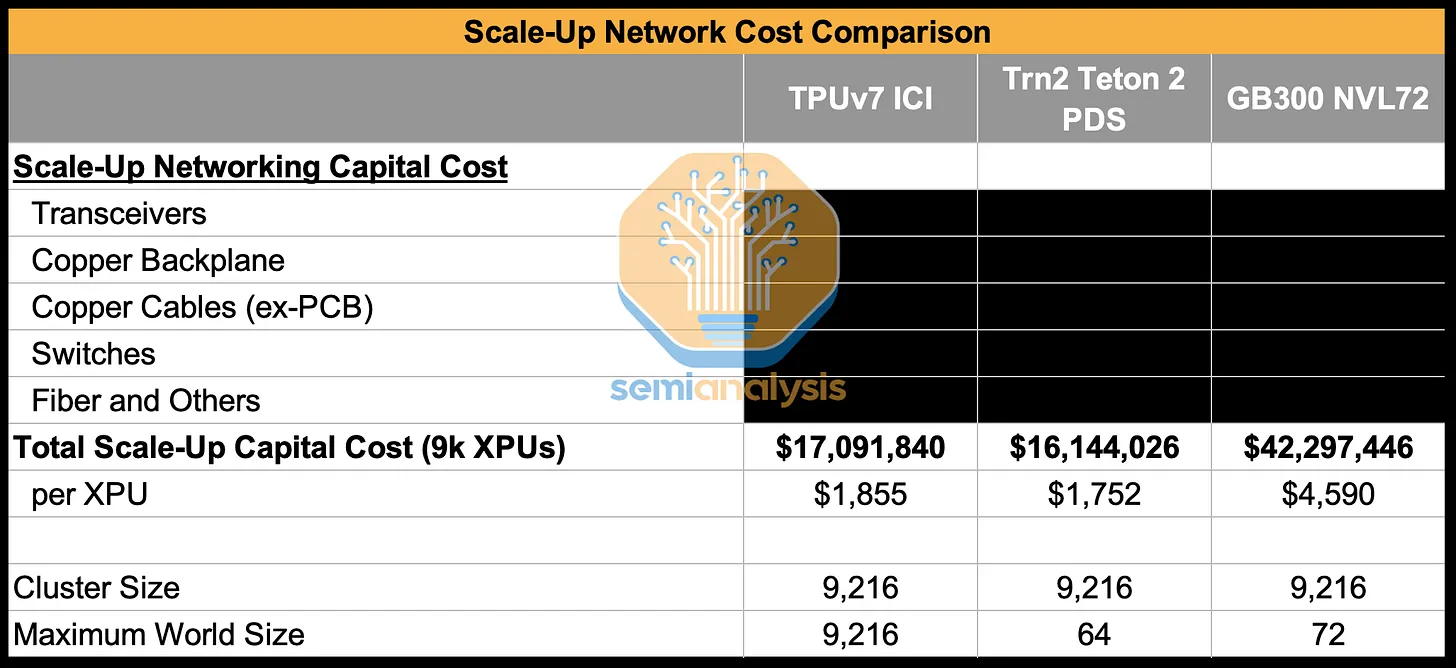
- TCO 优势突出,TPUv7 内部使用时 TCO 较 GB200 服务器低 44%,对外租赁时 TCO 较 GB200 低 30%、较 GB300 低 41%;
- 集群扩展性及灵活性领先,集群通过 ICI 3D Torus 网络支持最大 9216 颗芯片,OCS 技术实现数千种拓扑组合,适配多样并行需求且故障可快速重构。
三、TPU 对谷歌更为重要的意义在于构建全栈 AI 生态,而非出售 TPU 本身:通过芯片与模型架构协同设计,实现算力成本与效率最优,并赋能云业务,利用较低成本的 TPU 赚取高于其他云服务商的利润。长期竞争格局来看,TPU 完全颠覆英伟达 GPU 的概率较小,而较大概率作为英伟达 GPU 的补充,服务特定属性的客户群体:
- 英伟达凭借规模优势深度绑定供应链,在获取供应链资源方面具备最强的优先级和议价权;
- 谷歌 XLA 编译器、运行时代码仍未完全开源,导致 外部开发者在调试优化时面临较高技术门槛,尤其对缺乏定制化开发能力 的中小客户而言,适配成本显著高于 GPU。
- TPUv8 升级幅度有限,而英伟达 Rubin 系列升级显著,缩小了 TCO 差距,且英伟达过去已证明了一年一迭代的能力,后续 Feynman 接力 Rubin 维持一年一迭代节奏,英伟达技术领先性有望持续领跑。TPU v8 设计较为保守,整体性能提升较为温和,沿用 HBM3E 内存,在 TPU v8AX 上提供 9.8TB/s 的带宽;英伟达 Rubin 采用 HBM4 内存,带宽提升至 20TB/s,功率从最初计划的 1800W 激进提升至 2300W(提升28%),缩小了和 TPU v8 的 TCO 差距。应该看到,英伟达已建立稳定的 一年一迭代节奏,持续保持技术代差优势。
【谷歌路线以及 TPU 的技术优势】
一、关于谷歌的路线:Anthropic 交易标志着这一努力中的一个重要里程碑:谷歌云 CEO 托马斯·库里安在谈判中发挥了核心作用。谷歌很早就做出了承诺,积极投资 Anthropic 的融资轮次,甚至同意放弃投票权,并将其所有权上限设定为 15%,以扩大 TPU 在谷歌内部之外的使用。
- TPU 集群长期以来一直与英伟达的 AI 硬件不相上下,但它主要支持谷歌的内部工作负载。按照谷歌的典型风格,即使在 2018 年向谷歌云平台(GCP)客户开放 TPU 之后,也从未将其完全商业化。这种情况正开始改变。在过去几个月里,谷歌动员了整个技术栈的力量,通过谷歌云平台将TPU提供给外部客户,或者作为商业供应商销售完整的TPU系统。由于基础实验室中有前 DeepMind 的 TPU 人才,这一策略的实施变得更加顺利,这使得 Anthropic 能够在包括 TPU 在内的多种硬件上训练 Sonnet 和 Opus 4.5。
- 谷歌已经为 Anthropic 建造了一个大型设施。
二、成本优势显著,与英伟达形成差异化优势
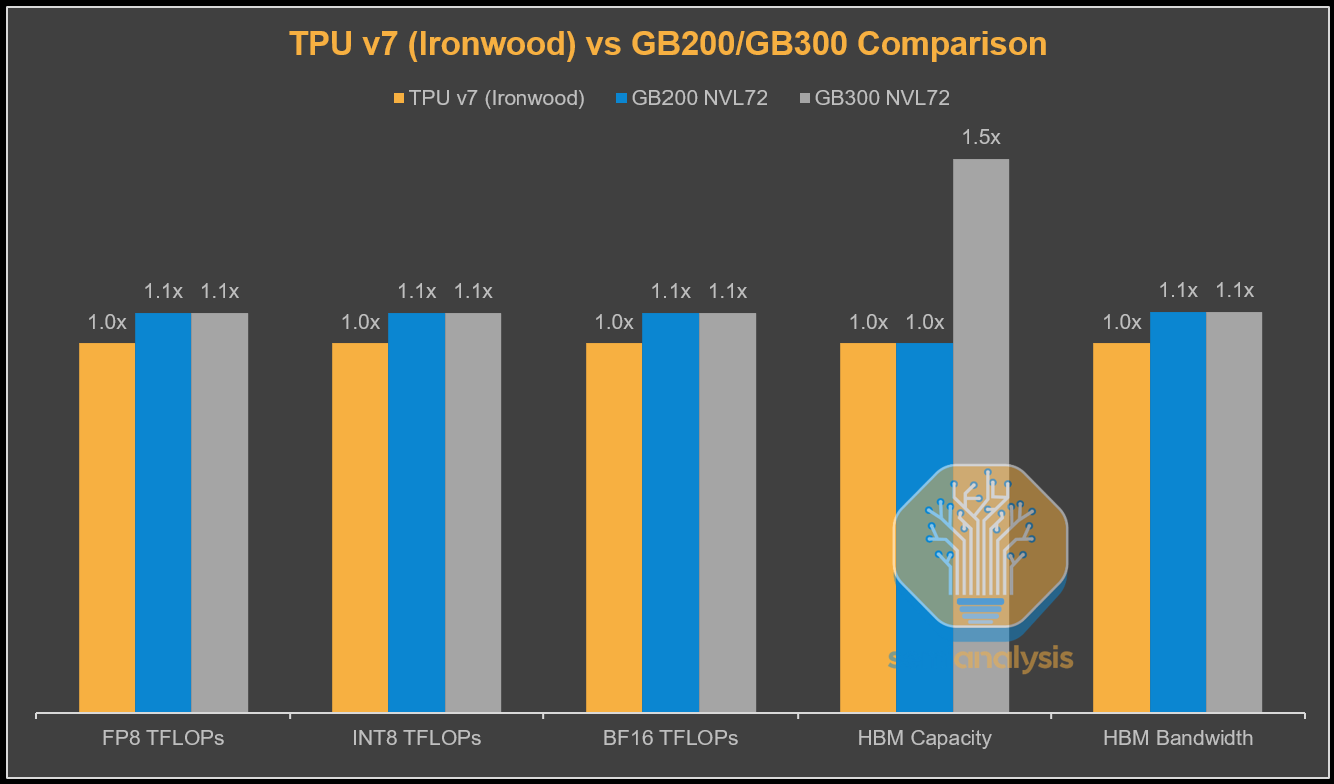
- TPU 技术迭代与性能追赶:设计理念转向大语言模型优化,TPU v7(Ironwood)性能逼近英伟达旗舰 GPU:采用 N3E 工艺,HBM3E 容量 192GB、带宽 7380GB/s,FP8 算力 4614 TFLOPs,与英伟达 GB200 差距缩小,上市时间仅晚几个季度;从 v4 到 v7,算力、带宽持续提升,功耗优化,v6 相比 v5p 算力翻倍。
- 成本效益优势显著:TPU v7 总拥有成本(TCO)大幅低于英伟达 GB200/GB300,内部版每小时仅 1.28 美元(GB200 为 2.28 美元);FP8 算力、内存带宽、内存容量的单位 TCO 均优于英伟达,息税前利润率高于多数 GPU 云交易,成为 GCP 差异化优势。
三、谷歌的 ICI 扩展网络,是英伟达 NVLink 唯一真正的竞争对手。
- ICI 3D Torus 架构核心优势:以 64 个 TPU 组成的 4x4x4 立方体为基本单元,支持 3D 环面扩展,最大规模达 9216 个 TPU;通过铜缆 + 光收发器 + OCS 实现连接,具备超大规模、高可重构性(支持数千种拓扑)、立方体可替代性、低成本(比同类交换网络省钱)、低延迟等优势。
谷歌与 Anthropic 的交易细节
交易细节
该交易的第一阶段涉及 40 万个 TPUv7 Ironwoods,成品机架价值约 100 亿美元,博通将直接向 Anthropic 出售这些产品。
- Anthropic 是博通在最近一次财报电话会议中提到的第四个客户。Fluidstack 将负责现场安装、布线、老化测试、验收测试以及远程运维工作,Anthropic 则将物理服务器的管理工作外包出去。数据中心基础设施将由 TeraWulf(WULF)和 Cipher Mining(CIFR)提供。
剩余的 60 万个 TPUv7 单元将通过谷歌云平台(GCP)出租。
- 预估,这笔交易的已签约未交付订单(RPO)为 420 亿美元,占谷歌云平台第三季度报告的 490 亿美元积压订单增长的大部分。
未来几个季度,与 Meta、OAI、SSI 和 xAI 达成的额外交易可能会为谷歌云平台(GCP)带来更多的 RPO 以及直接的硬件销售。
WULF Compute 与 Fluidstack 的交易,以及谷歌
**虽然其他超大规模企业已经扩大了自己的场地并获得了大量的托管空间,但谷歌的行动则更为迟缓。核心问题在于合同和管理方面。**每一个新的数据中心供应商都需要一份主服务协议,而这些协议涉及数十亿美元、多年期的承诺,自然会涉及一些行政流程。然而,谷歌的流程尤其缓慢,从初步讨论到签署主服务协议,往往需要长达三年的时间。谷歌的这种变通办法对那些希望转向人工智能数据中心基础设施的新云服务提供商和加密货币矿工具有重大影响。谷歌没有直接租赁,而是提供了一种信贷支持,即一种表外“欠条”,以便在 Fluidstack 无法支付其数据中心租金时介入。

这张图展示了 WULF Compute 与 Fluidstack 的交易,以及谷歌在其中的参与角色,结合信息可解读为:谷歌通过 “股权 + 信贷担保” 的方式,间接支持 Fluidstack 与 WULF 的大型数据中心租赁项目,而非直接提供硬件租赁服务。
核心交易:WULF 与 Fluidstack 的租赁合作
- WULF Compute 与 Fluidstack 签订了3 份 10 年期租约,涉及 Lake Mariner 数据中心的 CB-3、CB-4 及新增的 CB-5 项目,合计提供超 360MW 的关键 IT 负载(CB-5 单项目就新增 160+MW)。
- 合同价值:初始 10 年期约 67 亿美元;若行使 10 年延期选项,可额外增加约 90 亿美元收入。
- 交付节点:360+MW 的合同容量预计 2026 年底前交付。
谷歌并未直接向 Fluidstack 提供硬件租赁,而是通过两种方式参与:
- 持股支持:持有 WULF 约 14% 的股份,该持股结构是为了在建设期间向贷款人提供保障。
- 信贷担保:为 Fluidstack 的债务提供32 亿美元的担保,以支持项目的债务融资。
Ironwood 已接近 Blackwell
TPU 设计理念明显转变
迎来大语言模型时代后,谷歌的TPU设计理念发生了明显转变。可以从最近两代专为大语言模型设计的 TPU 中看到这一点:TPUv6 Trillium(Ghostlite)和TPUv7 Ironwood(Ghostfish)就体现了这种变化。
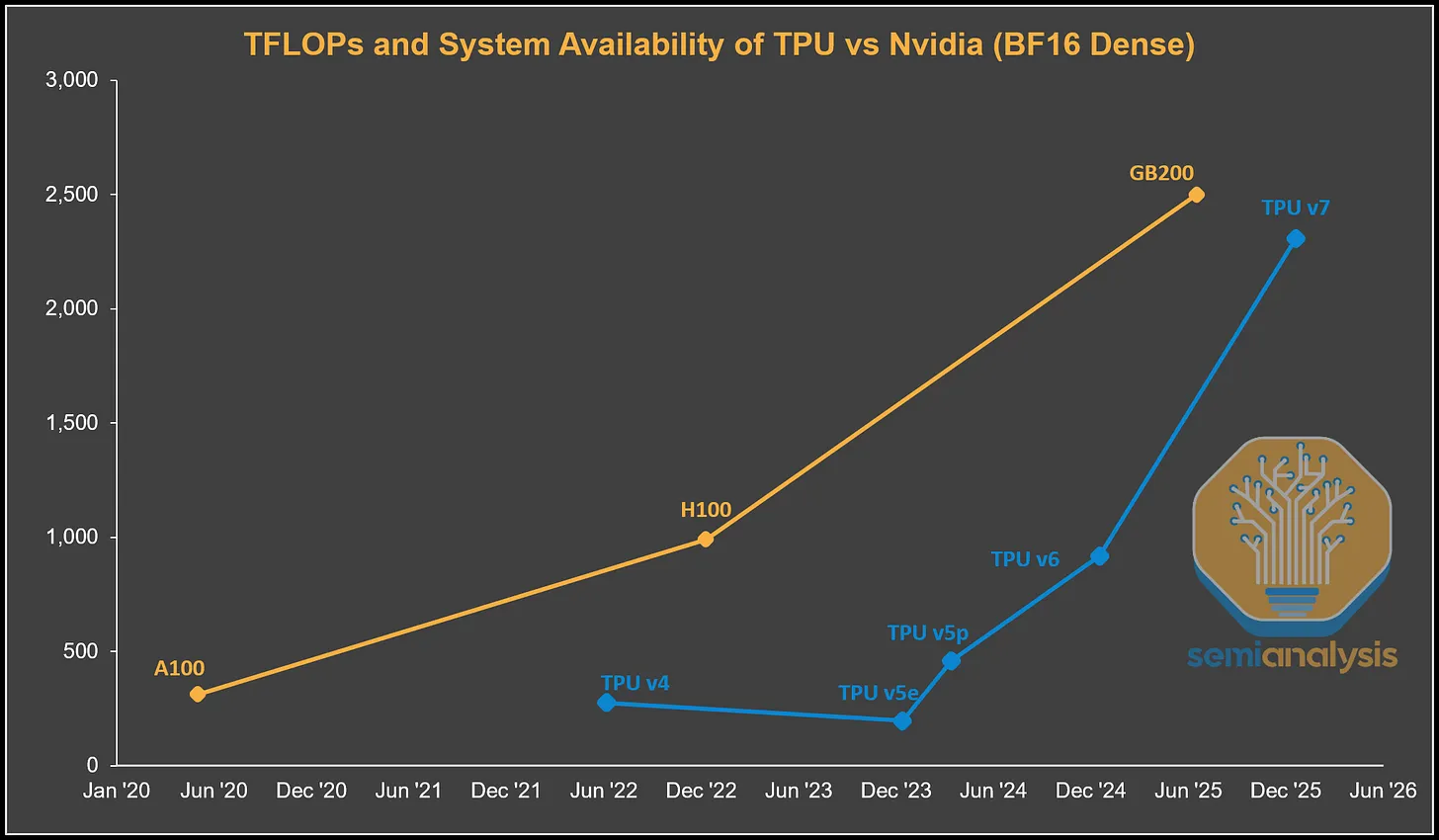
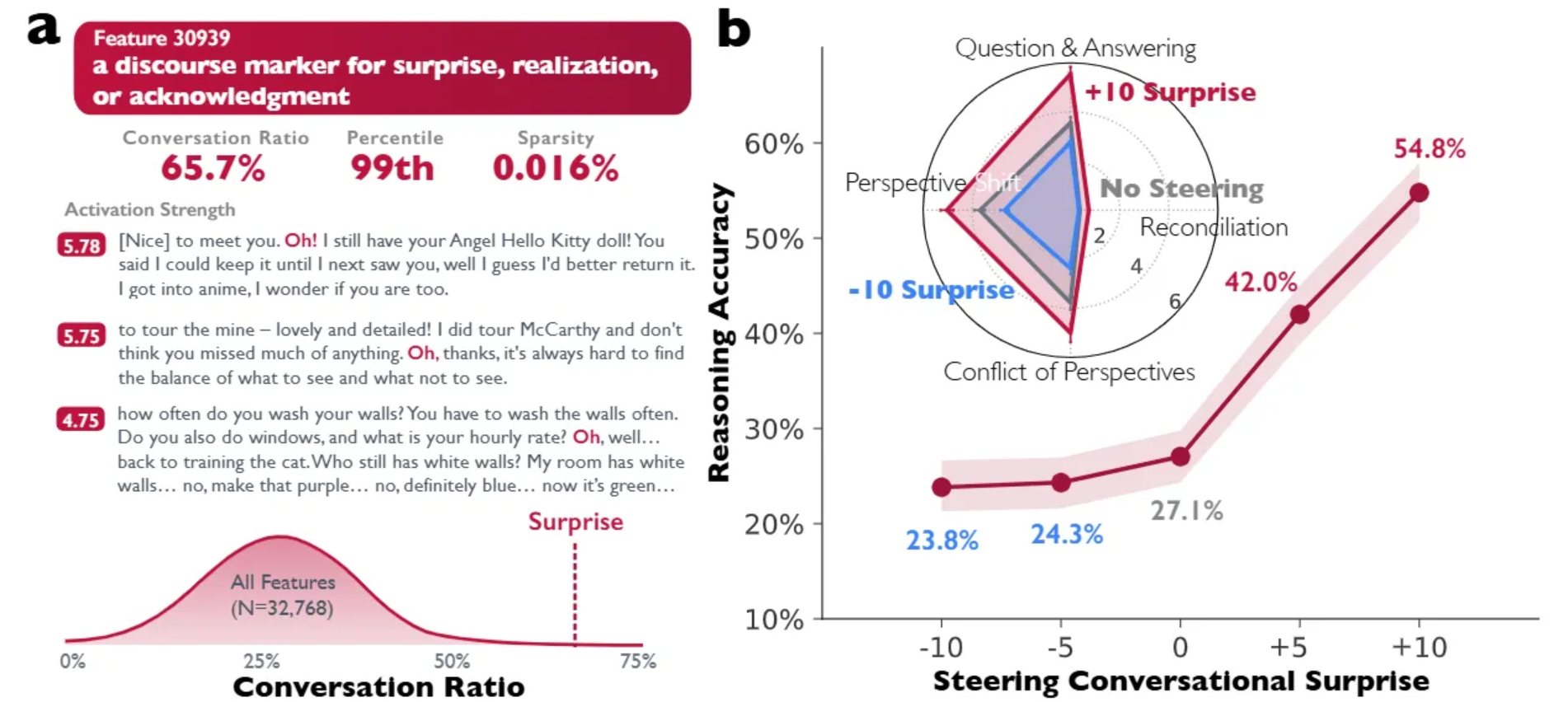
从下面的图表中可以看到,TPU v4 和 v5 的计算吞吐量远低于当时英伟达的旗舰产品。TPU v6 在浮点运算性能上非常接近H100/H200,但它比 H100 晚推出了两年。到了 TPU v7,差距进一步缩小,其服务器仅晚几个季度上市,同时提供的峰值理论浮点运算性能几乎达到了同一水平。
- TPU v6 Trillium 与 TPU v5p 采用相同的 N5 Node,硅片面积相近,但峰值理论浮点运算能力却惊人地提升了两倍,同时功耗显著降低。
- 对于Trillium,谷歌将每个脉动阵列的规模从128×128 瓦片扩大到 256 × 256 瓦片,扩大了四倍,这种阵列规模的增大带来了计算能力的提升。
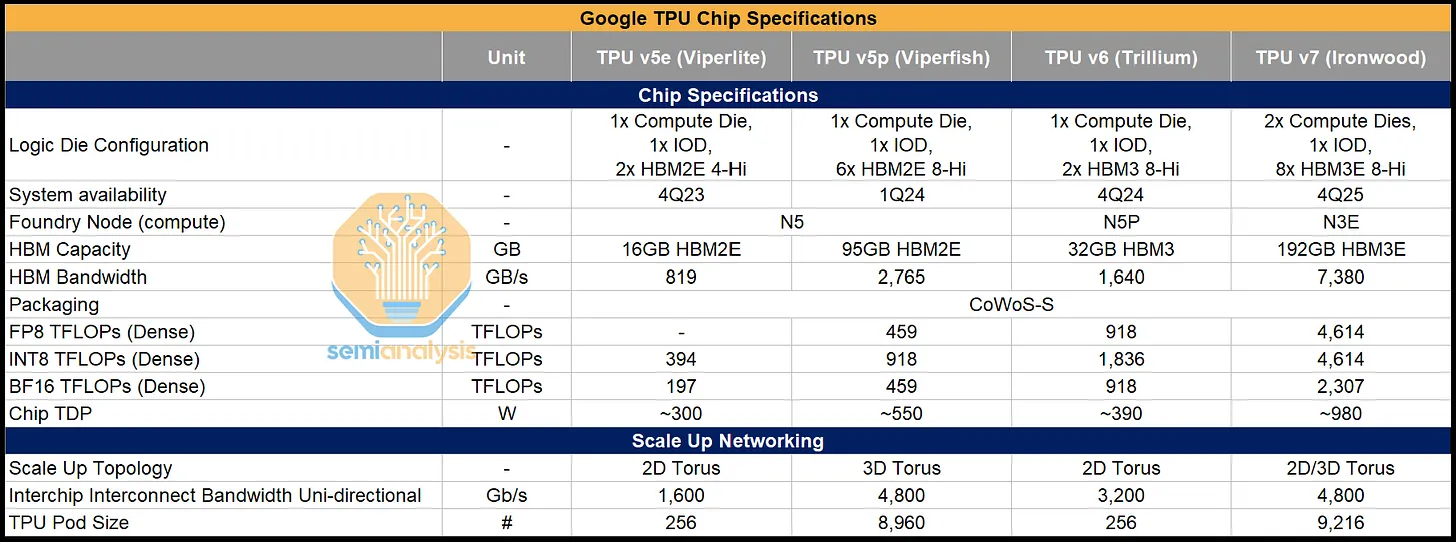
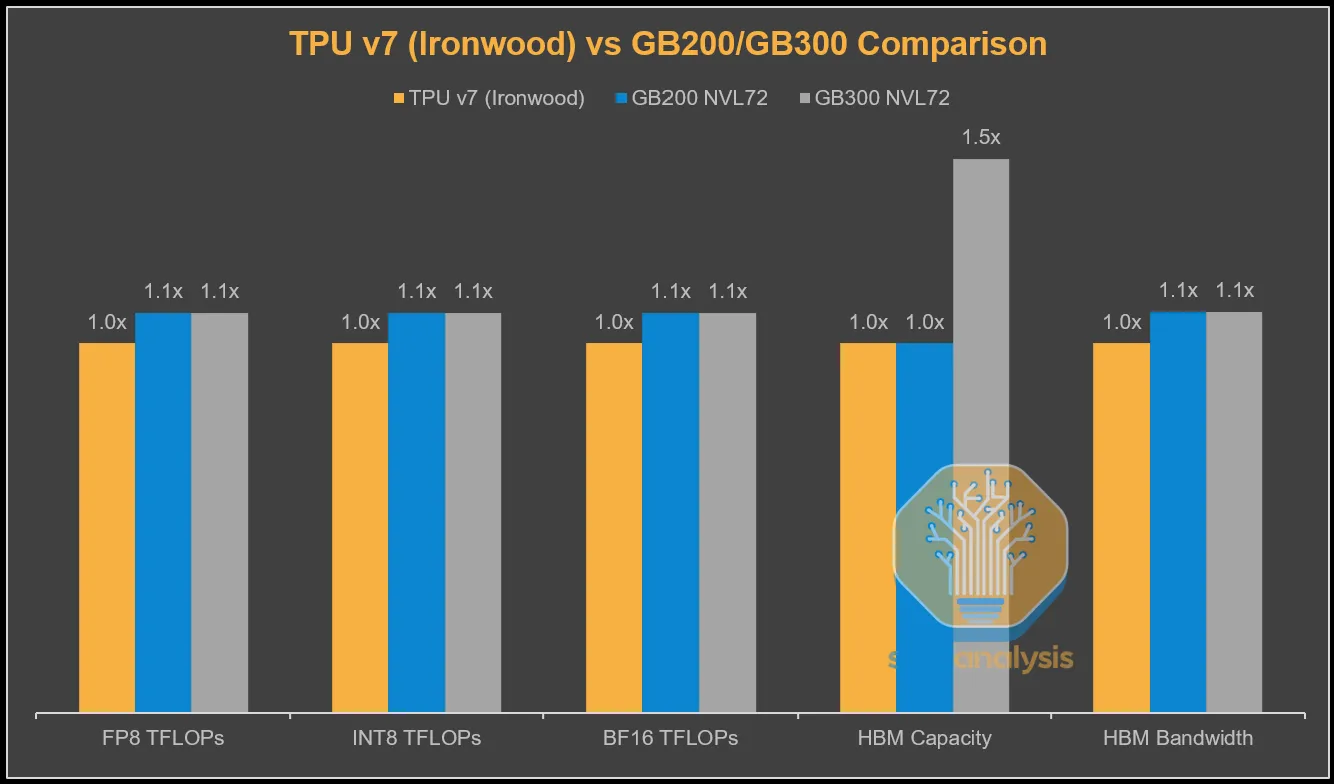
TPU v7 Ironwood 是下一个迭代版本,谷歌在浮点运算能力、内存和带宽方面几乎完全缩小了与英伟达相应旗舰GPU的差距,尽管其全面上市时间比 Blackwell 晚了一年。与 GB200 相比,其浮点运算能力和内存带宽仅略有不足,配备 8-Hi HBM3E 时的容量与 GB200 相同,当然,这与配备 12-Hi HBM3E、容量为 288GB 的 GB300 相比存在明显差距。
理论上的绝对性能是一回事,但重要的是 每总拥有成本(TCO Total Cost of Ownership)的实际性能。
每总拥有成本(TCO Total Cost of Ownership)的实际性能
虽然谷歌通过博通采购张量处理单元(TPU)并支付高额利润,但这远低于英伟达的利润,英伟达不仅在其销售的图形处理器(GPU)上获利丰厚,在包括中央处理器(CPU)、交换机、网络接口卡(NIC)、系统内存、线缆和连接器在内的整个系统上都能赚取高额利润。从谷歌的角度来看,这使得全3D环面配置下每块Ironwood芯片的总拥有成本(TCO)比 GB200 服务器的总拥有成本低约 44%。
这远远弥补了峰值 FLOPs 和峰值内存带宽约 10% 的缺口。这是从谷歌及其采购TPU服务器的价格角度来看的。
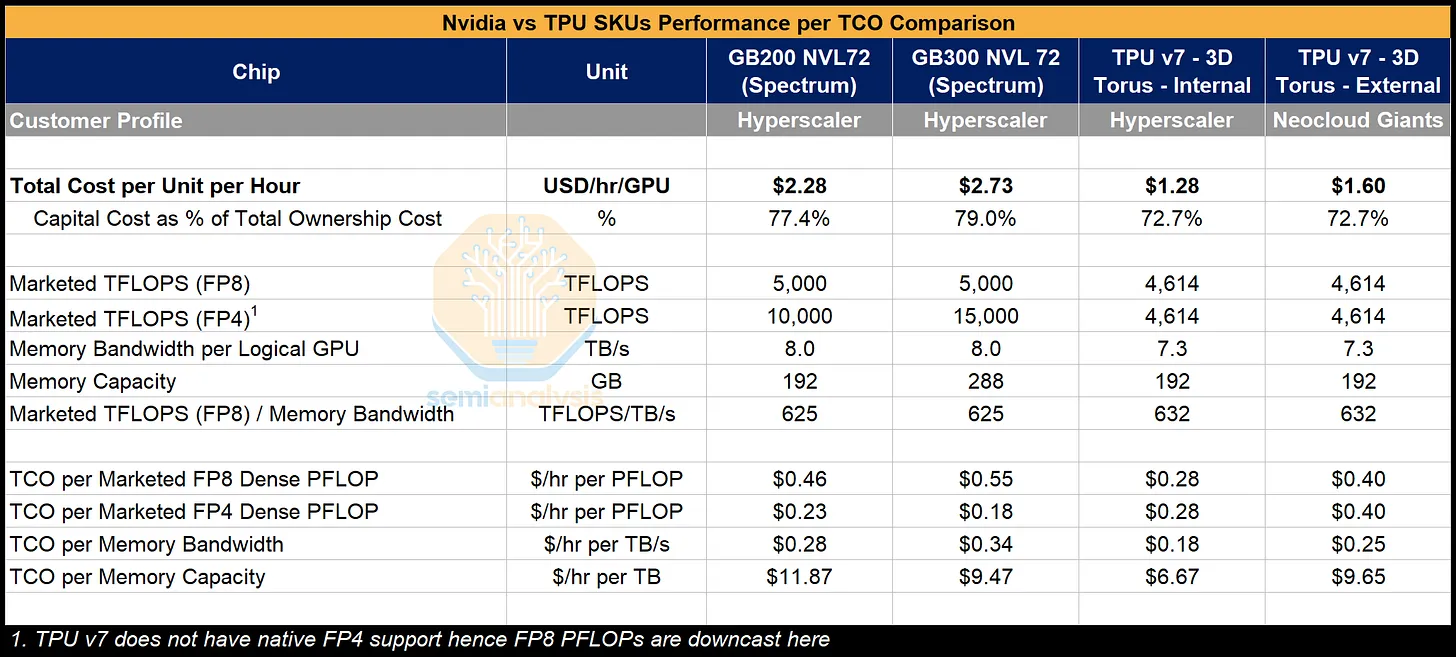
谷歌 TPU v7 的成本效率显著高于英伟达 GB200/GB300:虽然 TPU 的标称算力、带宽略低,但单位算力、内存对应的总成本(TCO)更低,尤其在 FP8 精度场景下优势明显;而英伟达的 FP4 高算力仅在特定场景有价值,但 TPU 不支持原生 FP4。
核心成本数据(每小时 / 每单元)
单位小时总成本:
TPU 显著更低 —— 内部 TPU 仅$1.28/小时,外部TPU为 $1.60 / 小时;而英伟达 GB200 是 $2.28/小时、GB300 达 $2.73 / 小时。
资本成本占比:
英伟达(77.4%~79.0%)略高于 TPU(72.7%),说明 TPU 的运营成本占比相对更低。
“成本 - 性能” 效率(核心对比维度)
FP8 算力的 TCO:
TPU 内部版仅$0.28/每PFLop·小时,远低于英伟达GB200($0.46)、GB300($0.55);外部TPU也仅$0.40。
内存带宽的 TCO:
TPU 内部版$0.18/每TB/s·小时,大幅低于英伟达($0.28~$0.34)。
内存容量的 TCO:
TPU 内部版$6.67/每TB·小时,同样优于英伟达($9.47~$11.87)。
TPU v7 的经济效益
**TPU v7的经济效益显示出更高的息税前利润率(与其他观察到的大型GPU云交易);只有 OCI 与 OpenAI 的合作接近这一水平。**即使考虑到博通在芯片级物料清单上的利润率叠加,谷歌仍能获得比商品化程度高得多的GPU交易高得多的利润率和回报。这正是TPU体系使谷歌云(GCP)成为真正差异化的云服务提供商(CSP)的地方。与此同时,像微软Azure这样ASIC项目举步维艰的公司,只能局限于在纯粹的商用硬件租赁业务中获得较为平庸的回报。
芯片间互连(ICI)——扩展横向扩展超大规模的关键
基本组成单元:4×4×4 Cube
谷歌用于 TPUv7 的 ICI 扩展网络的基本组成单元是一个由 64 个 TPU 组成的 4x4x4 三维环面。每个包含 64 个 TPU 的 4x4x4 立方体对应一个包含 64 个 TPU 的物理机架。这是一个理想的尺寸,因为所有 64 个TPU都可以相互电连接,同时仍能容纳在一个物理机架中。
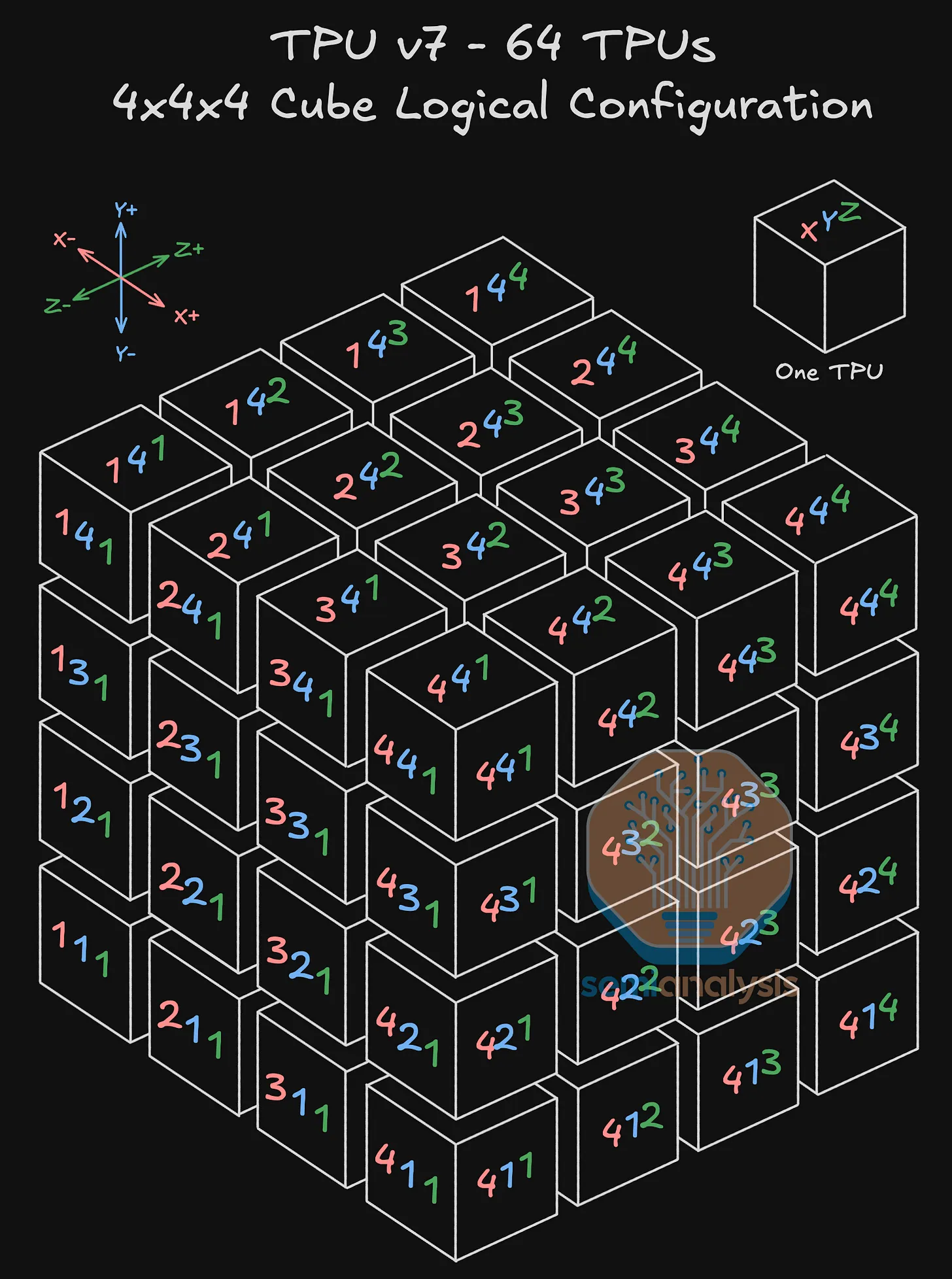
这些 TPU 以 3D 环形结构相互连接,每个 TPU 总共连接 6 个相邻节点:在 X 、 Y 和 Z 轴的每个轴上各连接 2 个逻辑上相邻的 TPU。
每个 TPU 通过计算托盘内的 PCB 线路始终与另外 2 个 TPU 相连,但根据该 TPU 在 4x4x4 Cube 中的位置,它将通过直接连接铜缆(DAC)或光收发器与另外 4 个相邻 TPU 相连。
4x4x4 立方体内部的连接通过铜缆实现,而 4x4x4 立方体外的连接(包括回绕至立方体另一侧的连接以及与相邻 4x4x4 立方体的连接)将使用光收发器和光交叉连接器(OCS)。下图展示了一个 3D 环面网络:Z+ 面上的 TPU 2,3,4 通过 800G 光收发器(800G Optical Transceiver)并经由一个 OCS,与Z-面上的 TPU 2,3,1 建立了回绕至 Z 轴对面的连接。
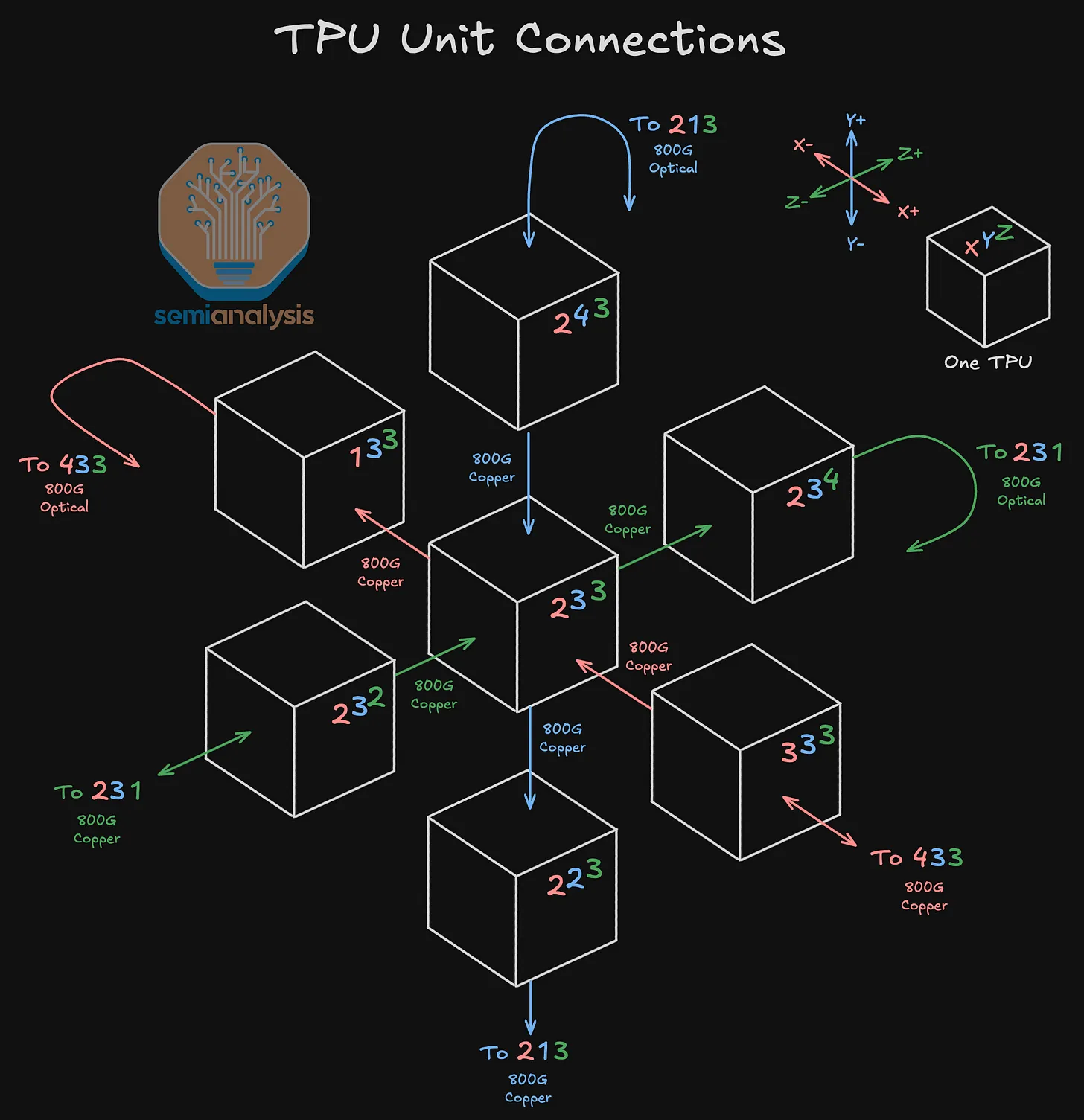
如上所述,除了始终通过 PCB 线路连接的 2 个相邻 TPU 外,TPU 还将根据其在 4x4x4 立方体中的位置,使用 DAC、收发器或两者的组合连接到另外 4 个相邻的TPU。
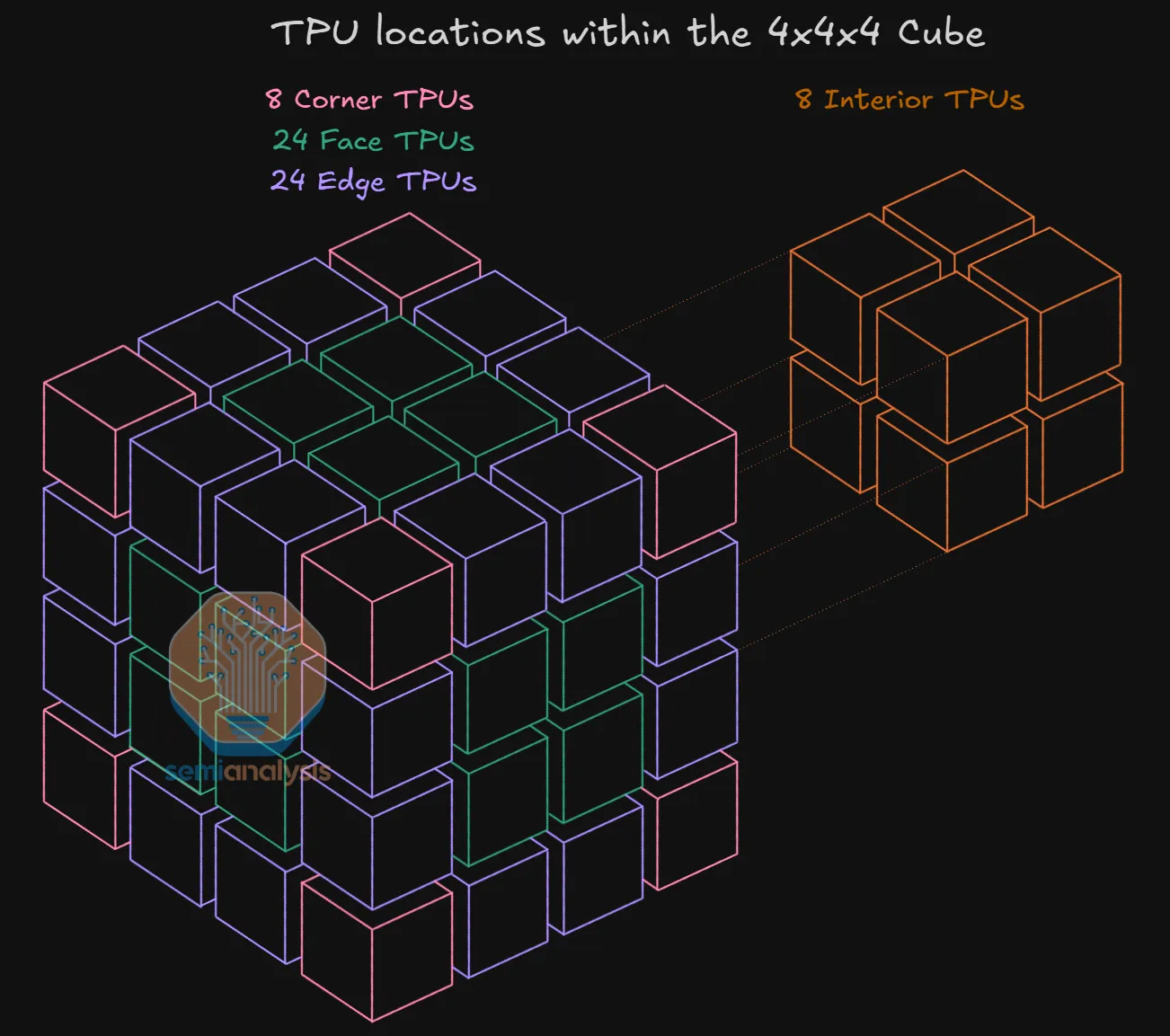
4x4x4 立方体内部的 TPU 将仅通过 DAC 连接到其他 4 个相邻 TPU,立方体表面的 TPU 将通过 3 个 DAC 和 1 个光收发器进行连接,立方体边缘的 TPU 将通过 2 个光收发器和 2 个DAC进行连接,而立方体角落的TPU将通过 1 个DAC和 3 个光收发器进行连接。要记住某个 TPU 将使用多少个收发器,只需看该 TPU 有多少个面朝向立方体的“外部”即可。
上图以及下表总结了各种位置类型的 TPU 数量,可用于得出每个 TPU v7 配备 1.5 个光收发器的连接比例。这些收发器与光电路交换机(OCS)相连,光电路交换机可实现 4x4x4 立方体之间的连接。
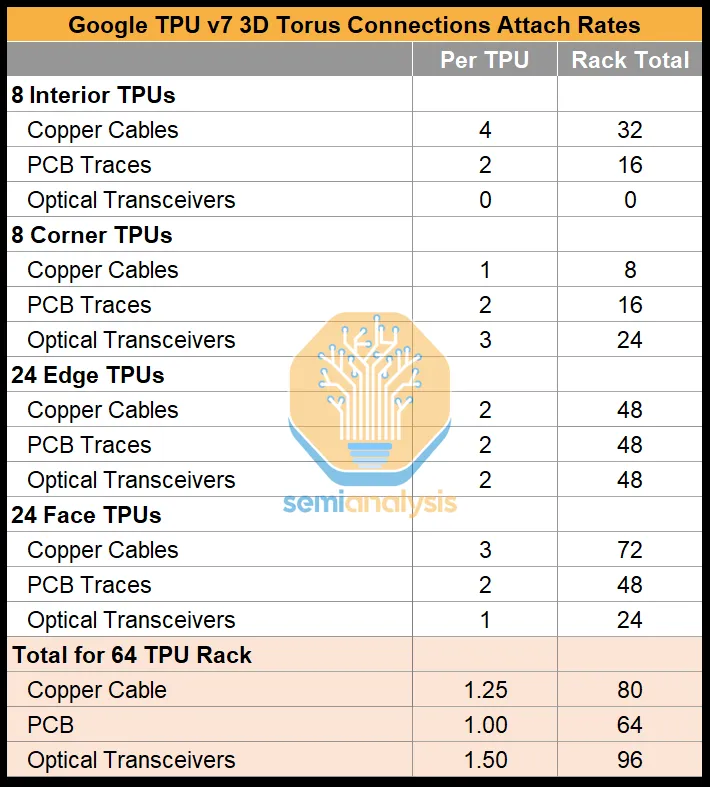
以下是TPU v7 3D 环面机架连接组件的分类统计清单,清晰呈现不同位置 TPU 的连接配置及机架总量:
一个 64 颗 TPU 连接组件配置
| TPU 类型 | 数量 | 铜缆数量 | PCB 走线数量 | 光收发器数量 |
|---|---|---|---|---|
| 内部 TPU(立方体内部) | 8 | 4 | 2 | 0 |
| 角落 TPU(立方体顶点) | 8 | 1 | 2 | 3 |
| 边缘 TPU(立方体棱边,非顶点) | 24 | 2 | 2 | 2 |
| 面 TPU(立方体表面,非棱边) | 24 | 3 | 2 | 1 |
机架总连接组件数量
| 连接组件类型 | 机架总量 |
|---|---|
| 铜缆 | 80 |
| PCB 走线 | 64 |
| 光收发器 | 96 |
内部 TPU 仅依赖铜缆 + PCB 走线完成机架内连接,无需光收发器;角落 / 边缘 / 面 TPU 通过光收发器实现跨机架的 3D 环面扩展,支撑大规模集群的低延迟通信。
将多个 64 TPU Cube 连接在一起
谷歌的ICI扩展网络独具特色,它允许将多个 64 个 TPU 的 4x4x4 立方体以 3D 环面结构连接在一起,从而创建大规模的全局规模。TPUv7 宣称的最大全局规模为9216 个TPU,但如今,谷歌支持将 TPU 配置为多种不同的切片规模,范围从 4 个 TPU 一直到 2048 个TPU。
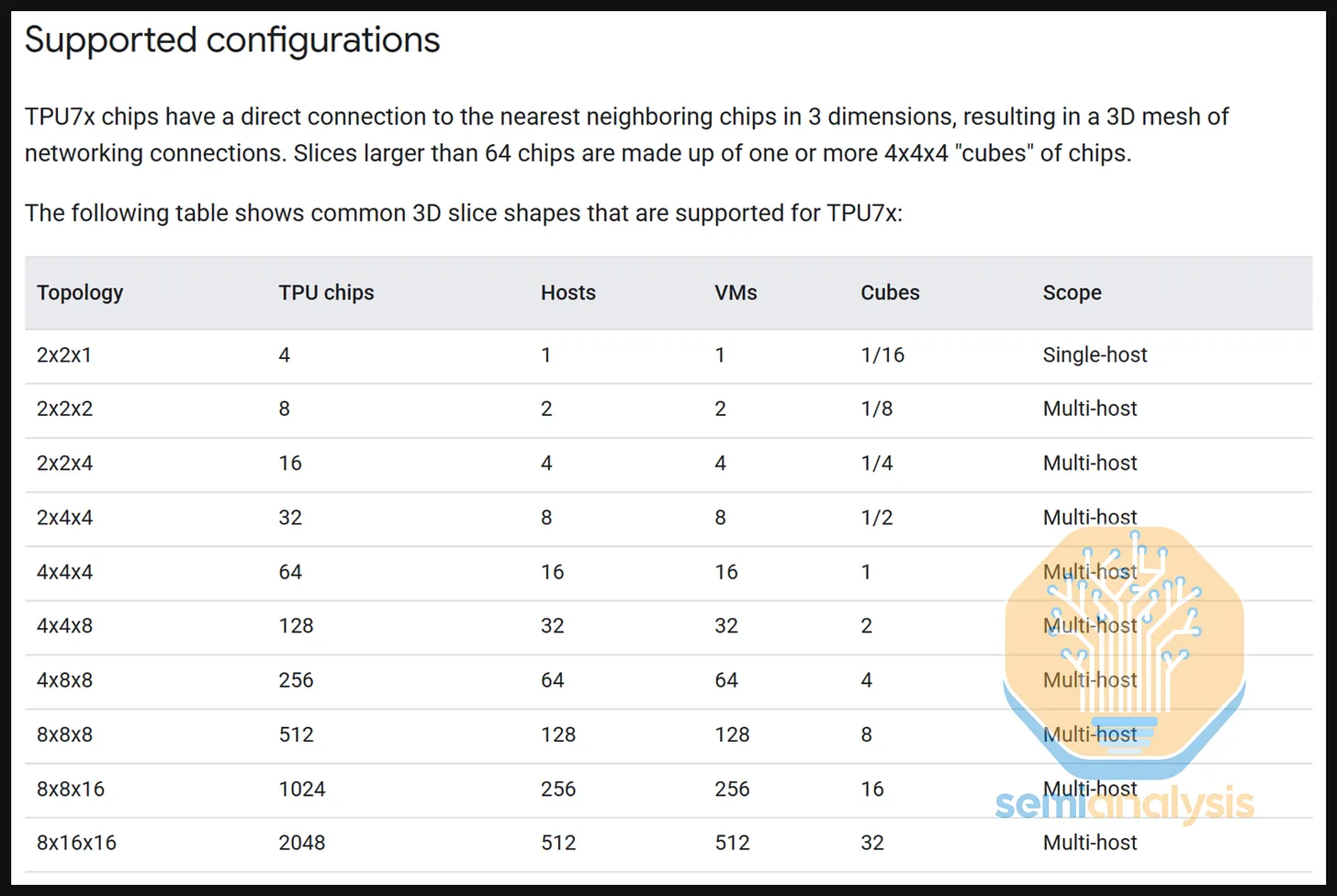
要了解环绕连接和立方体间连接是如何建立的,先看看如何在 4x4x4 的拓扑结构中创建一个 64 TPU 切片。
**使用由 64 个 TPU 组成的 4x4x4 单位立方体(对应一个物理的 64 TPU 机架)来构建这种拓扑结构。**4x4x4 立方体内部的所有 8 个 TPU 都可以通过铜缆与所有 6 个相邻 TPU 完全连接。如果某个 TPU 沿特定轴没有内部相邻的 TPU,它会进行环绕并连接到立方体另一侧的TPU。例如,TPU 4,1,4在Z+方向没有内部相邻的TPU,因此它会使用一个800G光收发器连接到分配给Z轴的光交叉连接(OCS),该 OCS 被配置为将此连接导向立方体的Z-侧,从而连接到 TPU 4,1,1。在Y-方向,TPU 1,1,1 会使用光收发器连接到 Y 轴 OCS,以链接到 TPU 1,4,1 的 Y+ 侧,依此类推。
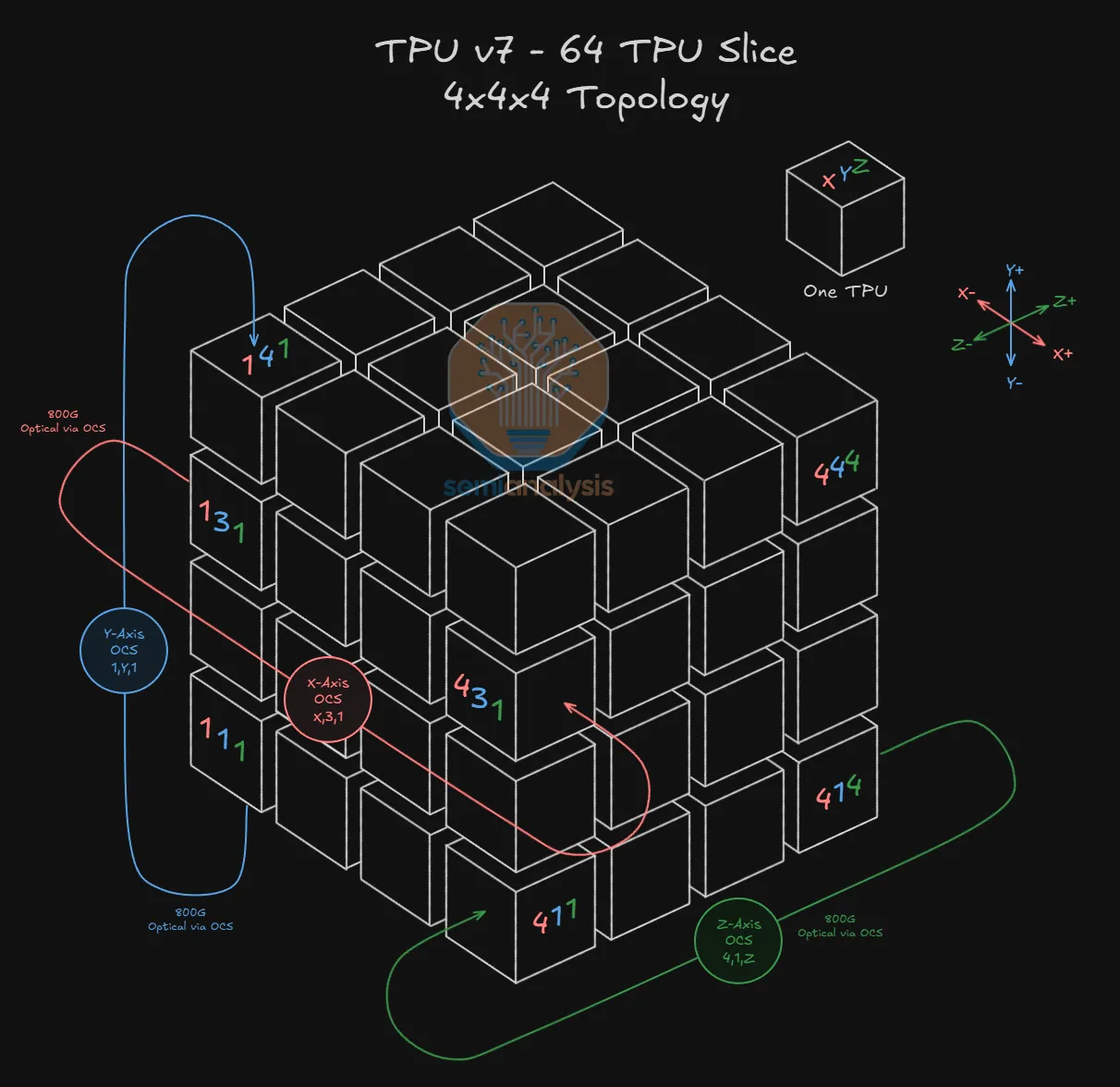
4x4x4 立方体的每个面将通过 16 个不同的 OCS 进行连接:每个面的每个 TPU 对应一个 OCS。
例如,在下图中,在X+面上,TPU 4,3,2 连接到 OCS X,3,2 的输入端。OCS X,3,2 的输入端还将连接到 9216 个 TPU 集群中所有 144 个 4x4x4 立方体的 X+ 面上相同的TPU索引(4,3,2)。OCS X,3,2 的输出端随后将连接到集群中每个立方体上相同的 TPU 索引,不过这次是在X-面上——因此它将连接到集群所有144个立方体上的TPU 1,3,2。下图展示了立方体 A 的 X+ 面上的所有 16 个 TPU 如何通过 16 个 OCS 连接到立方体 B 的 X- 面上的 16 个 TPU。
这些连接使得任何立方体的“+”面都能与其他任何立方体的“-”面相连,从而在形成切片时实现立方体的完全可互换性。
有两个限制需要简要指出。首先,特定面上同一索引的TPU永远不能直接连接到不同的索引——因此 TPU 4,3,2 永远不能配置为连接到 TPU 1,2,3。其次,由于OCS本质上起到配线架的作用——连接在输入侧的TPU不能“回环”连接到同样连接在OCS输入侧的任何其他TPU——例如,TPU 4,3,2 永远不能连接到 TPU 4,3,3。因此,“+”面上的任何TPU都永远不能连接到其他任何立方体的“+”面,“-”面上的任何TPU也永远不能连接到其他任何立方体的“-”面。
96 TPU:4×4×8 Cube
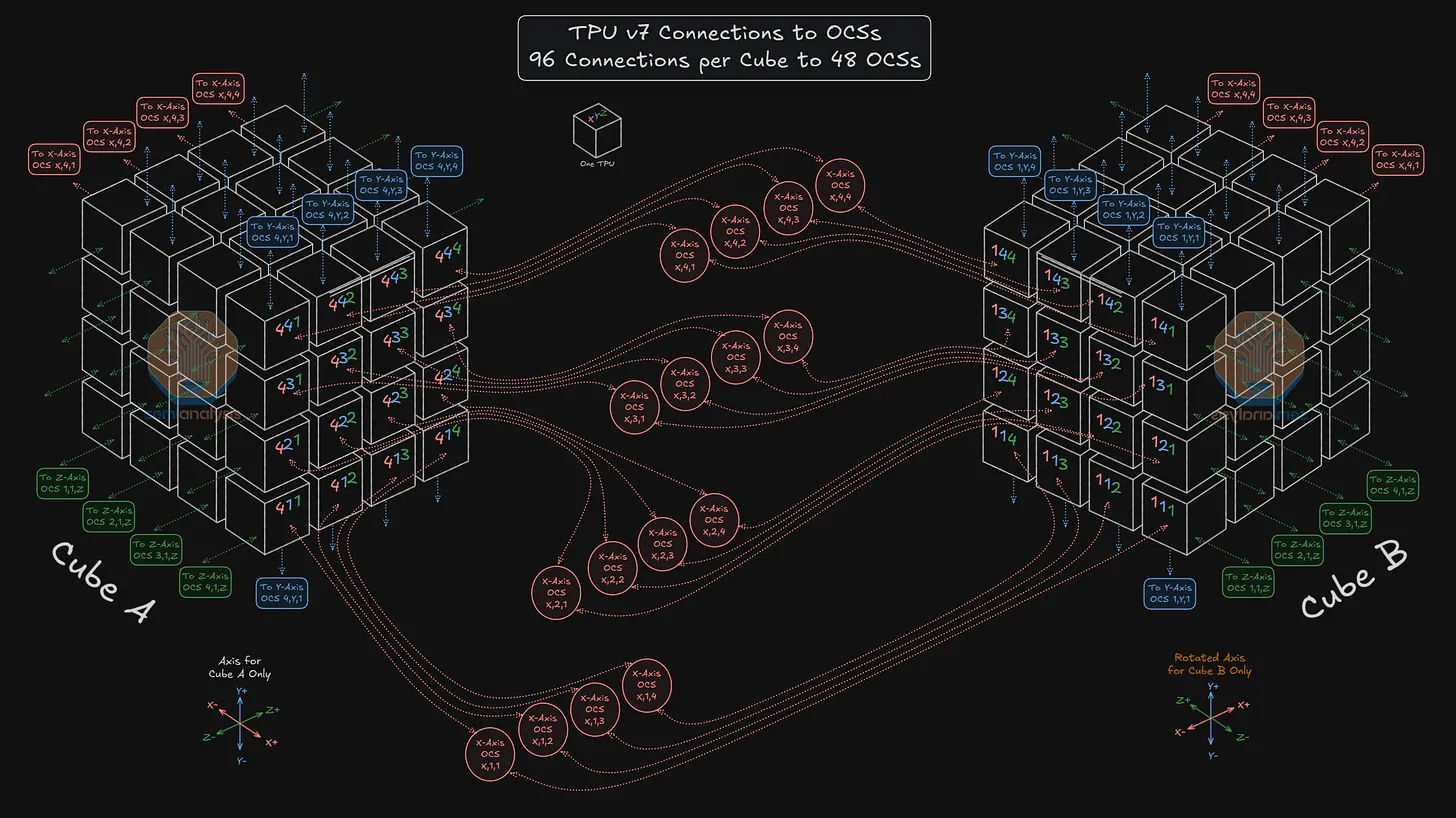
进一步来看,看看如何设置一个 4x4x8 的拓扑结构。在这种配置中,通过沿 Z 轴连接两个 64 TPU 的 4x4x4 立方体来扩展切片。在这种情况下,OCS 将重新配置 TPU 4,1,4所连接的光端口,使其现在连接到 TPU 4,1,5,而不是像独立的 4x4x4 拓扑结构那样绕回连接到 TPU 4,1,1。进一步扩展来看,这两个 4x4x4 TPU立方体的每个立方体的 Z- 面和 Z+ 面将各有 16 个光连接,总共有64根光纤连接到16个 Z 轴 OCS 中。
需要提醒读者的是,下面所描绘的 A 立方体和 B 立方体不一定物理上相邻。相反,它们通过 OCS 连接,并且可能分别位于数据中心的完全不同的位置。
4096 TPU:16×16×16 Cube
现在将转向一个更大的拓扑结构:16x16x16 拓扑结构,这使 TPU 数量达到 4096 个。在这个拓扑结构中总共使用 48 个 OCS 来连接 64 个立方体,每个立方体包含 64 个TPU。在下图中,每个彩色立方体代表一个包含 64 个 TPU 的 4x4x4 立方体。以右下角的 4x4x4 立方体为例,这个立方体通过 OCS 沿着 Y 轴与相邻的立方体相连。
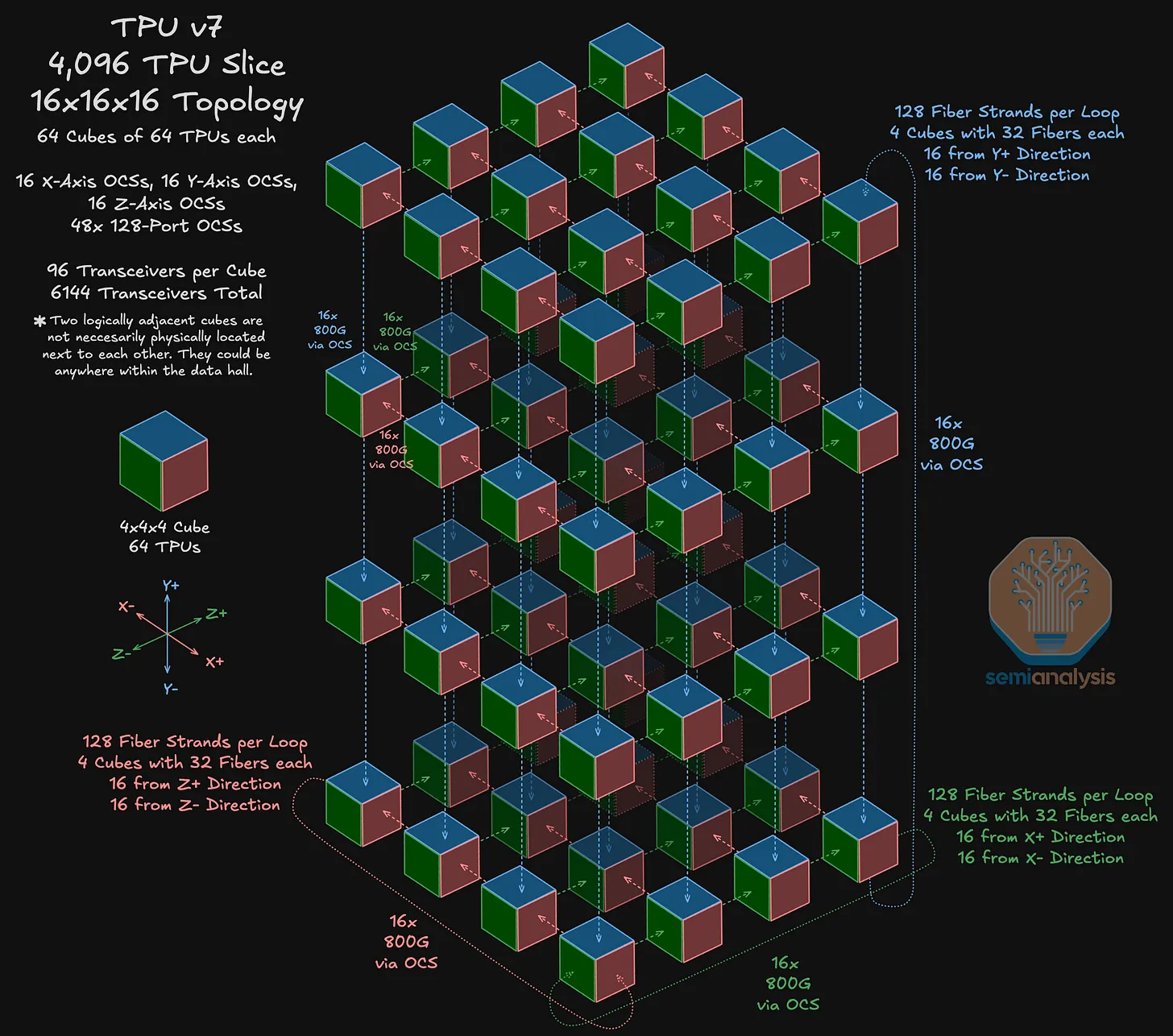
9216 个 TPU 的最大规模是由 144 个 4×4×4 的立方体构成的,每个立方体需要 96 个光学连接,总共需要 13824 个端口。将总端口需求除以 288(每个 OCS 有 144 个输入端口和 144 个输出端口),意味着需要 48 个144×144 的 OCS 来支持这一最大规模。
为什么要使用 Google 的 ICI 3D Torus 架构?
**超大规模:**最明显的优势是 TPUv7 Ironwood 支持的 9216 个 TPU的超大最大规模。尽管由于有效吞吐量降低这一缺点,9216 的最大切片规模可能很少被使用,但数千个 TPU 的切片能够且确实被普遍使用。这远远大于商业加速器市场和其他定制芯片供应商中常见的 64 或 72 个 GPU 的规模。
**可重构性与可替代性:**光交叉连接器(OCSs)的使用意味着网络拓扑本身支持网络连接的重新配置,以支持大量不同的拓扑结构——理论上可达数千种。谷歌的文档网站列出了10种不同的组合(本节前面的图片),但这些只是最常见的3D切片形状,实际上还有更多可供选择。
- 可重构性还为广泛多样的并行性打开了大门。在 64 或 72 个 GPU 的规模下,不同的并行组合通常局限于64的因数。而对于ICI横向扩展网络,实现能精确匹配所需的数据并行、张量并行和流水线并行组合的拓扑结构的可能性十分丰富。
- 开放式连接系统(OCSs)允许将任何立方体的任意“+”面与任何其他立方体的“-”面相连,这一事实意味着立方体具有完全的可替代性。任何一组立方体都可以组成切片。因此,无论出现任何故障、用户需求变化或使用情况改变,都不会阻碍新拓扑切片的形成。
**成本更低:**谷歌的ICI网络成本低于大多数可扩展交换网络。尽管由于使用了环形器,所采用的FR光学器件可能略贵一些,但网状网络减少了所需交换机和端口的总数,并消除了交换机之间连接产生的成本。
**低延迟和更好的局部性:**TPU之间使用直接链接意味着,对于物理位置彼此靠近或被重新配置为直接相互连接的TPU,可以实现更低的延迟。彼此靠近的TPU也具有更好的数据局部性。
谷歌的软件战略:拥抱开源推理生态
谷歌调整了面向外部客户的软件战略,并已对其TPU团队的关键绩效指标(KPIs)以及该团队为人工智能/机器学习(AI/ML)生态系统做出贡献的方式进行了重大修改:
Massive engineering effort on PyTorch TPU “native” support
对PyTorch TPU“原生”支持的大规模工程投入
Massive engineering effort on vLLM/SGLang TPU support
在 vLLM / SGLang 的 TPU 支持方面投入大量工程资源
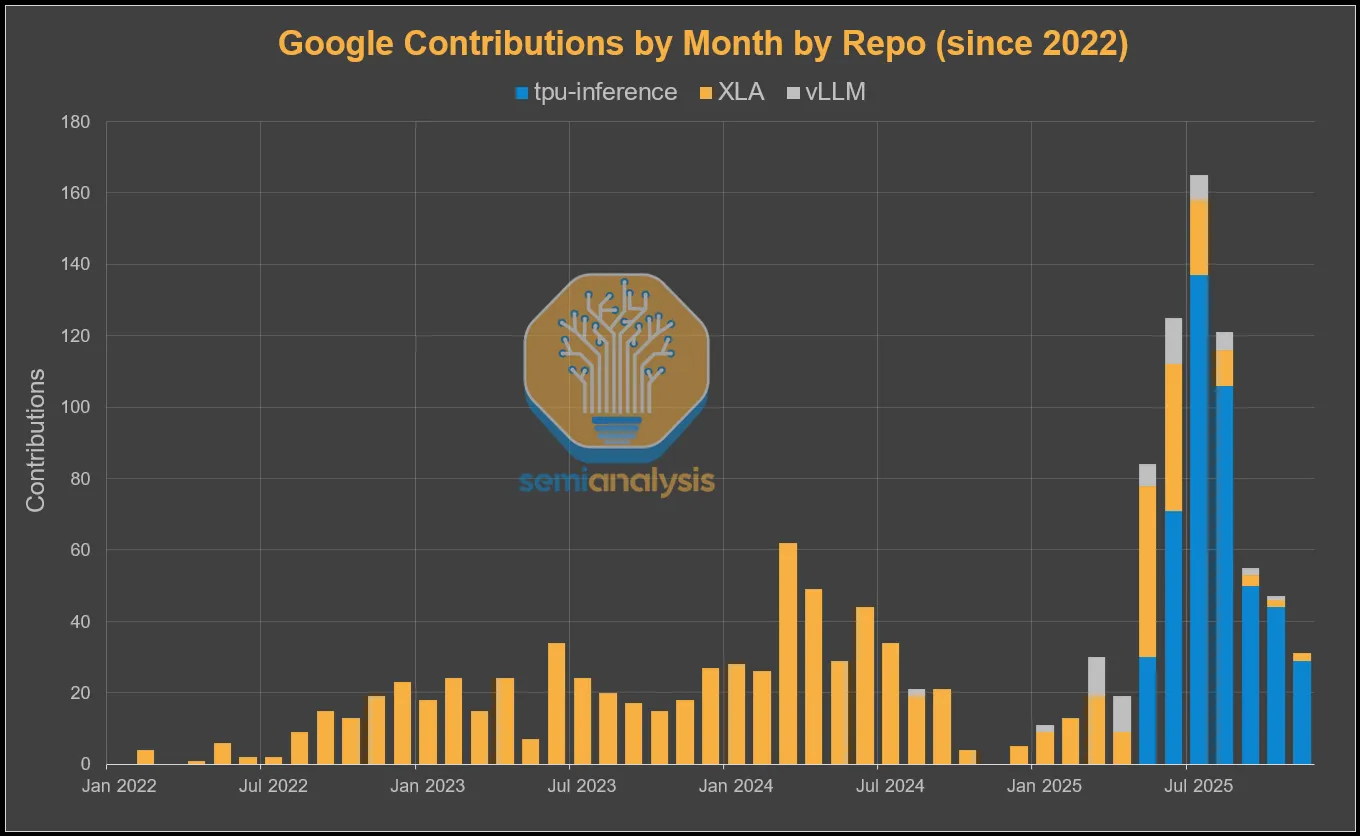
**通过查看谷歌在各种TPU软件代码库中的贡献数量,不难发现其外部化策略。**我们可以看到,从3月开始,vLLM的贡献量有了显著增长。随后在5月,“tpu-inference”代码库被创建,这是官方的vLLM TPU统一后端,从那以后,相关活动便层出不穷。
Pytorch
传统上,谷歌只在 Jax/XLA:TPU 框架(以及已停用的 TensorFlow/TF-Mesh)上提供一流支持,而将 TPU 上的 PyTorch 视为二等公民。它依赖于通过PyTorch/XLA 进行的 Lazy Tensor Graph Capture,而非提供 First-class Eager Execution Mode。此外,它不支持 PyTorch 原生分布式 API(torch.distributed.*)或 PyTorch 原生并行 API(DTensor、FSDP2、DDP 等),而是依赖于一些怪异的树外 XLA SPMD API(torch_xla.experimental.spmd_fsdp、torch_xla.distributed.spmd 等)。这给那些习惯了 GPU 上 PyTorch 原生 CUDA 后端、并尝试转向 TPU 的外部用户带来了非原生的次等体验。

10月,谷歌的“神奇队长”罗伯特·亨特在 XLA 代码库中悄然宣布,他们将从非原生的惰性张量后端转向“原生” TPU PyTorch 后端,该后端默认支持即时执行,并将集成 torch.compile、DTensor 以及 torch.distributed 等应用程序接口。他们将通过使用 PrivateUse1 TorchDispatch 键来实现这一目标。此举主要是为了满足 Meta 的需求,Meta 近期重新燃起了购买 TPU 的兴趣,且不愿转向 JAX。这也将让那些喜欢 PyTorch 而不喜欢 JAX 的用户也能使用 TPU。
这种新的 PyTorch 与 TPU 的结合,将为习惯在 GPU 上使用 PyTorch 的机器学习科学家提供更顺畅的过渡,使他们能够转而在 TPU 上使用 PyTorch,并利用 TPU在总拥有成本(TCO)方面更高的性能优势。
vLLM & SGLang

**CUDA生态系统占据优势的另一个领域是开放式生态推理。**从历史上看,vLLM 和 SGLang 将 CUDA 作为一等公民提供支持(而 ROCm 则是二等公民)。现在,谷歌希望加入 vLLM 和 SGLang 的开放式推理生态系统,并已宣布通过一种非常“独特”的集成方式,为 vLLM 和 SGLang 提供 TPU v5p/v6e 的 beta 版支持。
vLLM 和 SGLang 目前通过将 PyTorch 建模代码转换为 JAX,并利用现有的成熟 JAX TPU 编译流程来实现这一点。未来,一旦 PyTorch XLA RFC #9684(即原生TPU PyTorch 后端)得到实现,vLLM 和 SGLang 计划评估是否转而使用该后端,而非通过 TorchAX 将建模从 PyTorch 转换为 JAX。
谷歌和 vLLM 声称,这种向 jax 路径的转换不需要对 PyTorch 建模代码做任何修改,但鉴于 vLLM TPU 目前支持的模型数量极少,目前对此表示怀疑。
此外,谷歌已将部分TPU内核开源并集成到vLLM中,例如经过TPU优化的分页注意力内核、计算-通信重叠的GEMM内核以及其他一些量化矩阵乘法内核。
谷歌的产业链信息
| Basket 名称 | 公司代码 | 公司中文名称 | 英文全称 | 核心业务领域 | 产业链角色 | 与 Basket 主题关联(AI 芯片核心逻辑) |
|---|---|---|---|---|---|---|
| TPU Basket(张量处理单元相关) | GOOG US | 谷歌 | Alphabet Inc. | 互联网搜索、AI 技术研发、TPU 芯片设计 | 芯片设计(TPU 发明者) | 全球首个 TPU(张量处理单元)研发方,用于自身 AI 模型训练 / 推理,开源 TPU 架构生态 |
| AVGO US | 博通 | Broadcom Inc. | 半导体组件、光纤通信、数据中心芯片 | 芯片设计 + 零部件供应 | 为 TPU 提供高速接口芯片、射频组件,支撑 TPU 与服务器的连接效率 | |
| LITE US | 鲁门特姆 | Lumentum Holdings Inc. | 光通信器件、激光组件、光学模块 | 光学零部件供应 | 提供 TPU 服务器所需的高速光模块(数据传输核心部件) | |
| CLS US | 康宁 | Corning Incorporated | 特种玻璃、光纤、半导体封装材料 | 材料供应 | 为 TPU 芯片封装、服务器机箱提供高耐热 / 高透光玻璃基板 | |
| TTMI US | 泰科电子 | TE Connectivity Ltd. | 工业连接器、传感器、射频组件 | 连接器件供应 | 提供 TPU 与主板、服务器的高可靠性连接器(信号传输关键部件) | |
| FIX US | 菲尼特里 | Finisar Corporation | 光通信模块、激光二极管、光学传感器 | 光模块供应 | 为 TPU 数据中心提供 100G/400G 高速光模块,保障 AI 算力集群通信 | |
| FLEX US | 伟创力 | Flex Ltd. | 电子制造服务(EMS)、服务器组装 | 制造服务提供商 | 承接 TPU 服务器的组装、测试业务,属于 AI 算力硬件制造环节 | |
| Nvidia Basket(英伟达生态相关) | NVDA US | 英伟达 | NVIDIA Corporation | GPU 设计、AI 芯片、自动驾驶芯片 | 核心芯片设计(生态主导) | 全球 AI 算力核心(GPU/HOLOCAUST 芯片),Basket 核心龙头,支撑 AI 训练 / 推理 |
| ORCL US | 甲骨文 | Oracle Corporation | 企业软件、云计算、数据库服务 | 云服务 + 软件生态 | 与 Nvidia 合作推出 Oracle Cloud Infrastructure(OCI),搭载 A100/H100 芯片提供 AI 云服务 | |
| MSFT US | 微软 | Microsoft Corporation | 操作系统、云计算(Azure)、AI 服务 | 云服务 + 软件生态 | Azure 云深度集成 Nvidia GPU,推出 Copilot AI 工具,是 Nvidia 芯片最大云客户之一 | |
| SMCI US | 超微电脑 | Super Micro Computer Inc. | 高性能服务器、AI 算力集群硬件 | 硬件集成商 | 专为 Nvidia GPU 设计 “Ultra Server”,是 AI 算力集群核心硬件供应商 | |
| 2382 TT | 台达电 | Delta Electronics, Inc. | 电源管理系统、工业自动化、散热方案 | 配套硬件供应 | 为 Nvidia GPU 服务器提供高效电源和散热解决方案(AI 算力功耗核心需求) | |
| 6601138 CH | 中芯国际 | Semiconductor Manufacturing International Corporation | 集成电路制造(晶圆代工) | 芯片制造 | 国内唯一能量产 14nm 芯片的代工厂,潜在为 Nvidia 供应链提供中低端芯片制造支持 | |
| 3231 TT | 大立光 | Largan Precision Co., Ltd. | 手机 / 服务器摄像头镜头、光学组件 | 光学零部件供应 | 为搭载 Nvidia 芯片的 AI 终端(如自动驾驶汽车、边缘计算设备)提供镜头 | |
| 3017 TT | 日月光 | Advanced Semiconductor Engineering, Inc. | 芯片封装测试、半导体制造服务 | 芯片封装测试 | 为 Nvidia GPU 芯片提供先进封装(如 CoWoS)测试服务,提升芯片性能 | |
| APH US | 安费诺 | Amphenol Corporation | 高频连接器、射频电缆、传感器 | 连接器件供应 | 提供 Nvidia GPU 与服务器主板的高频连接器,保障算力传输稳定性 | |
| 8210 TT | 联电 | United Microelectronics Corporation (UMC) | 集成电路制造(晶圆代工) | 芯片制造 | 为 Nvidia 供应链提供中低端芯片代工(如汽车级 AI 芯片),补充台积电产能 | |
| 2308 TT | 台积电 | Taiwan Semiconductor Manufacturing Company Limited | 全球领先集成电路制造(晶圆代工) | 核心芯片制造 | 独家代工 Nvidia A100/H100 等高端 AI 芯片(5nm/3nm 工艺),是 Nvidia 生态核心制造支柱 | |
| 2059 TT | 鸿海(富士康) | Hon Hai Precision Industry Co., Ltd. | 电子制造服务(EMS)、服务器组装 | 硬件制造集成商 | 组装 Nvidia GPU 服务器、AI 算力集群,是 Nvidia 硬件最大代工伙伴之一 | |
| 034020 KS | 三星电子 | Samsung Electronics Co., Ltd. | 半导体(存储 / 逻辑芯片)、电子设备 | 芯片制造 + 存储供应 | 为 Nvidia 提供 HBM(高带宽存储)芯片(AI GPU 核心配套),同时竞争高端芯片代工市场 | |
| Trainium Basket(亚马逊 AI 芯片相关) | AMZN US | 亚马逊 | Amazon.com, Inc. | 电子商务、云计算(AWS)、Trainium 芯片设计 | 芯片设计 + 云服务(生态主导) | 自研 Trainium 芯片(用于 AWS AI 训练),Basket 核心龙头,对标 Nvidia GPU |
| MRVL US | 迈威尔科技 | Marvell Technology Group Ltd. | 数据中心芯片、存储控制器、网络芯片 | 配套芯片设计 | 为 AWS Trainium 服务器提供存储控制器和网络接口芯片,优化数据传输效率 | |
| 6669 TT | 联发科 | MediaTek Inc. | 移动芯片、AI 边缘芯片、物联网芯片 | 芯片设计 | 与 AWS 合作推出边缘 AI 芯片,兼容 Trainium 生态,支撑边缘 AI 推理场景 | |
| 3661 TT | 纬创 | Wistron Corporation | 电子制造服务(EMS)、服务器组装、云计算硬件 | 硬件制造集成商 | 为 AWS 组装搭载 Trainium 芯片的 AI 服务器,属于 AWS 算力硬件核心代工厂 | |
| 2345 TT | 奇美电子 | Chi Mei Optoelectronics Corp. | 显示面板、光学组件、半导体材料 | 显示 / 材料供应 | 为 AWS Trainium 服务器提供高分辨率显示面板(数据中心监控场景)和光学材料 | |
| ALAB US | 奥罗拉微电子 | Aurora Labs Ltd. | 半导体设计工具、AI 芯片验证方案 | 设计工具供应 | 为 Trainium 芯片提供设计验证工具,加速芯片研发和量产效率 |
Reference
[1] (SemiAnalysis) TPUv7: Google Takes a Swing at the King
[2] (国泰海通证券) 《Gemini 3、TPU、端侧 AI 应用更新报告》 - 2025.12.02
TPU 与 GPU 的未来竞争格局态势
http://vincentgaohj.github.io/Blog/2025/12/03/TPU 与 GPU 的未来竞争格局态势/