State of AI 2025
关于硅谷投资人 Nathan Benaich 和他创办的 Air Street Capital 所撰写的报告 State of AI 2025 中的一些观点的深度解读。其中包含了一些技术工作,产业实证结论,以及 GW 数据中心的相关盈利研究。
重要结论
关于研究:推理的 Scaling Law 成为新焦点
- 推理计算的重要性被严重低估:传统上重视训练阶段的投入(Training Time),但研究表明,推理阶段(Inference Time)的扩展是释放模型潜力的另一个关键维度,可视为“横向扩展”。
- “小模型 + 复杂推理”可能是更优策略:在固定计算预算下,使用较小的模型并为其配备更复杂的推理策略(如思维链、树搜索等)生成更多Tokens,其性能往往优于单纯使用更大的模型。这为成本效益权衡提供了新思路,即在某些场景下部署中型模型并投入更多推理计算可能更经济高效。
- 存在收益递减规律:所有推理优化策略都受制于强烈的收益递减规律,投入的边际效益会逐渐降低。
关于技术演进:DeepSeek 的战略转向效率与生态
- 从性能追赶到综合优势构建:DeepSeek的演进路线(V3 → V3.1 → V3.2)表明其战略重心已从单纯追求模型性能,转向构建 “效率-成本-生态”三位一体的综合优势。
- 核心技术是稀疏注意力(DSA):V3.2通过自研的 Lightning Indexer 和 DSA 稀疏注意力机制,实现了长上下文推理速度的倍增和处理成本的大幅下降,使推理速度能随输入长度呈线性增长。
关于产业:市场加速,格局初定
- 英伟达的市值突破 4 万亿美元,在人工智能研究论文的相关领域占据了 90% 的份额,与此同时,定制芯片和新型云服务也在崛起。循环式的巨额交易为大规模扩张提供了资金支持。
- AI-First 公司增长进入“火箭模式”;OpenAI 在应用层断档领先;多模态生成应用收入疯涨;大模型答案引擎呈现“风格化。
- 随着 GW 集群的规划,电力成为了新的瓶颈,而电网限制也开始影响路线图和利润空间。
关于政策算力基础设施:军备竞赛与盈利模型
- 算力集群建设进入“吉瓦(GW)时代”:主要AI实验室(xAI, Meta, OpenAI, Anthropic)正在建设或计划在2026年投入使用的算力集群规模均达到约1吉瓦级别,集群规模成为实力和招聘的象征。
- 推理计算是为训练买单的关键:商业模型的核心在于,如何将模型生命周期中更多的计算分配给能产生收入的推理工作,并追求最高的利润率。推理利润率和计算分配策略直接影响投资回报。
- AI数据中心是资本密集型高毛利业务:以1GW数据中心为例:
- 资本支出(Capex)巨大:约500亿美元,其中计算硬件(GPU等)占比最高(60%)。
- 折旧与摊销(D&A)是主要成本:占总年度成本的 75% - 80%。
- 具备强大的盈利能力:尽管投入巨大,但精细化的财务模型显示,此类业务能够产生可观的运营利润(Operating Profit)和税后净利润(Contribution Profit),运营利润率可达 40% 左右。甲骨文与 OpenAI 的合作案例预测了其持续的盈利潜力。
基础前沿
针对推理的 Scaling Law
- Sam Altman: The intelligence of an AI model roughly equals the log of the resources used to train and run it.

The world will not change all at once; it never does. Life will go on mostly the same in the short run, and people in 2025 will mostly spend their time in the same way they did in 2024. We will still fall in love, create families, get in fights online, hike in nature, etc.
世界不会一蹴而就地发生改变;它从来都不是这样。短期内,生活大多会照旧进行,2025年的人们大多会以2024年的方式度过他们的时光。我们仍会坠入爱河,组建家庭,在网上争吵,在大自然中徒步等等。
But the future will be coming at us in a way that is impossible to ignore, and the long-term changes to our society and economy will be huge. We will find new things to do, new ways to be useful to each other, and new ways to compete, but they may not look very much like the jobs of today.
但未来将以一种无法忽视的方式向我们袭来,我们的社会和经济将发生巨大的长期变革。我们会找到新的事情去做,找到新的方式来彼此帮助,以及新的竞争方式,但它们可能与今天的工作大不相同。
CMU 的论文 《Inference Scaling Laws: An Empirical Analysis of Compute-optimal Inference for Problem-solving with Language Models》 给出了一个结论:**通过推理策略来扩展推理计算,可能比扩展模型参数在计算上更高效。此外,较小的模型与先进的推理算法相结合,在成本和性能方面呈现出帕累托最优的权衡。**例如,在 MATH 基准测试中,Llemma-7B 模型与树搜索算法配对后,在所有测试的推理策略上均持续优于 Llemma-34B 模型。
We find that using a smaller model and generating more tokens in an inference strategy often outperforms using a larger model at a fixed compute budget. This has implications for models deployed in the real world, where inference compute is constrained in various ways. Specifically, it is potentially beneficial to deploy smaller models with more sophisticated inference strategies for better cost-performance trade-off.
我们发现,在固定的计算预算下,使用较小的模型并在推理策略中生成更多的 Tokens,其性能往往优于使用较大的模型。这对于在现实世界中部署的模型具有重要意义,因为推理计算在多种情况下都受到限制。具体而言,部署较小的模型并采用更复杂的推理策略,可能有助于实现更优的成本效益权衡。
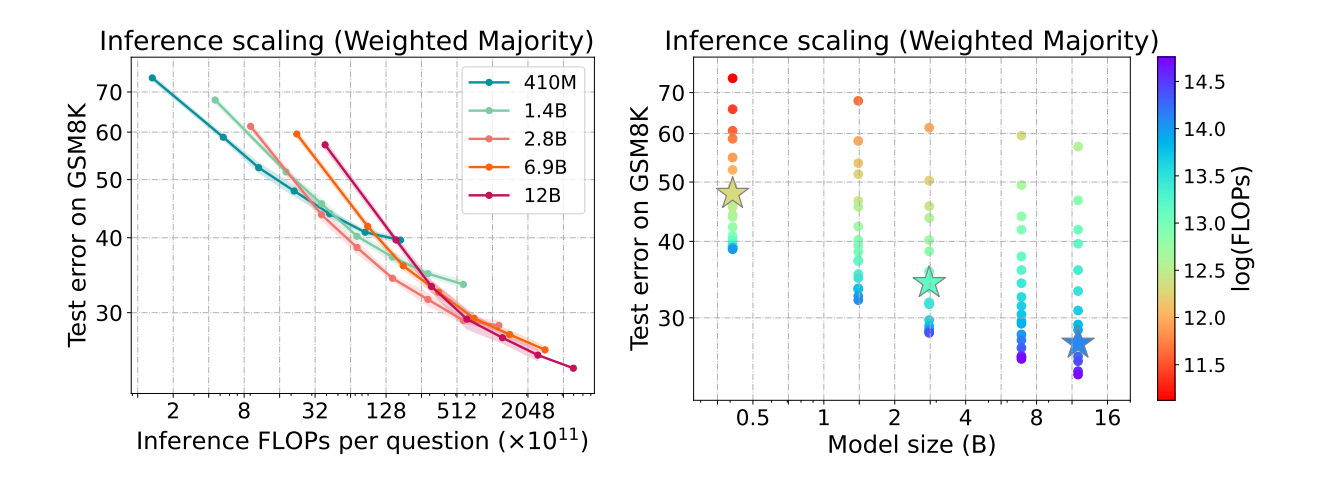
论文评估,随着推理计算量的增加,每种模型大小的错误率稳步下降,并在最后趋于收敛。以及最佳模型大小(对于 2⁴¹、2⁴⁴和 2⁴⁷次浮点运算,以星号显示)会根据推理时间的计算预算而变化。这有效的说明了 Inference Time 在实践中的重要程度,在目前是被远远低估了(相对于 Training Time),同时通过合理的组合(比如较小的模型+复杂的推理过程)的确能过获得更大的收益。
给定一个固定的总计算预算(训练+推理),如何在模型规模和推理计算之间进行分配,是未来系统优化的重要课题。有研究表明,对于某些任务,训练一个稍小的模型但为其配备大量的推理时计算(如采样),可能比直接训练一个巨大的模型但只做单次采样更高效。
所以在 Inference Time 的 Scaling Law 问题上可以总结如下:
- “大力出奇迹”在推理时也适用:即使不改变模型,通过投入更多推理计算(采样、思考),也能显著提升效果,尤其在不确定性高、需要创造力的任务上。
- 收益递减:所有推理时优化策略都受制于强烈的收益递减规律。
- 模型规模是基础:推理时计算的有效性高度依赖于模型本身的能力。一个能力不足的模型,即使给它再多的“思考时间”,也无法产生质的飞跃。
- 新的成本权衡:这引入了一种新的工程和成本权衡:是部署一个超大模型(高固定成本)进行简单推理,还是部署一个中型模型(低固定成本)但为其配备复杂的推理策略(高可变成本)?
总而言之,推理时间的 Scaling Law 揭示了模型能力释放的另一个维度:横向扩展。它不再仅仅追求模型的“大脑”更大,而是追求在解决问题时给予更长的“思考时间”,从而激发现有模型参数的潜力。
DeepSeek 的发展与演进
DeepSeek V3.2 技术细节
DeepSeek 发布了 V3.2,其通过 Lightning Indexer 来大幅提升效率,与之前的 V3.1 模型相比,长上下文推理速度提升了 2-3 倍,处理成本降低了 6-7 倍(Source: DeepLearning.AI)。本质上,V3.2 通过稀疏注意力机制使推理速度能随输入长度呈线性增长。
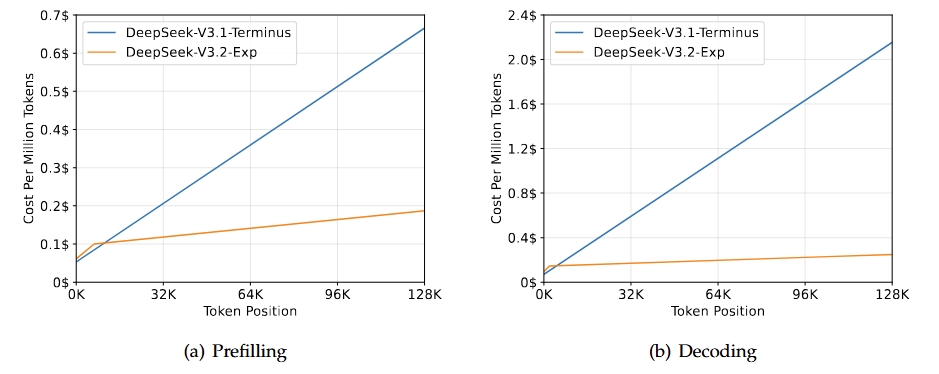
- 在预训练过程中,DeepSeek 通过 Lightning Indexer 的加权相似性函数从 21 亿个 Tokens 中训练以预测 DeepSeek-V3.1-Terminus 的稠密注意力机制会关注哪些 Tokens。随后在约 1000 亿个 Tokens 上对所有参数进行了微调,使其能与 Indexer 协同。
- 训练环节分为两个部分:Dense Warm-up Stage 和 Sparse Training Stage。
- Dense Warm-up Stage 主要作用是为 Lightning Indexer 提供初始参数,实现 Indexer 和主注意力分布对齐,为后面的稀疏矩阵的训练做基础。
- Sparse Training Stage 引入细粒度 Token 选择机制,也就是 Fine-grained Token Selection Mechanism,这一步的训练目的是让模型和 Indexer 共同适配 DSA 的稀疏注意力模式,并保证在这个模式下,模型的语言建模能力不显著变化或者下降。
- 在后训练过程中,目的是在“稀疏架构下补全多任务能力,验证 DSA 对性能的影响”,后训练也分为两个大部分:专家蒸馏 Specialist Distillation 和混合 RL 训练 Mixed RL Training。
- 专家蒸馏:研究团队通过将五个专业模型(经过预训练的 DeepSeek-V3.2 基础模型的不同版本,分别针对推理、数学、编程、智能体编程和智能体搜索进行了微调)蒸馏到 DeepSeek-V3.2-Exp 中,进一步对该模型进行了微调。
- 混合 RL 训练:研究团队依然应用了 GRPO (Group Relative Policy Optimization),将推理、智能体和人类对齐训练合并到一个阶段。这种方法避免了灾难性遗忘问题,即新学到的知识会取代旧知识,而这一问题通常会困扰多阶段强化学习。
- 在推理时,Indexer 会对每个历史 Tokens 与正在生成的 Tokens 的相关性进行评分。使用 FP8 精度(8 位浮点数,精度相对较低,但处理时所需的计算量更少)来快速计算这些分数。
- 基于这些分数,模型不再计算当前输入上下文中所有 Tokens 的注意力,而是选择并计算得分最高的 2048 个 Tokens 的注意力,显著降低了计算成本。
DeepSeek 的发展演进思路
总的来说,DeepSeek的演进路线图清晰地描绘了其战略重心从单纯追求模型性能,转向构建“效率-成本-生态”三位一体的综合优势。
- V3/R1 回答了“如何快速达到一线水平”的问题:重点是通过“后训练”优化,快速弥补与国际顶尖模型的能力差距
- 以基础模型 DeepSeek-V3-Base 为基座,通过后训练技术来激发模型潜力,使其在推理、编程等特定任务上表现更出色。引入了“深度思考”模式,进行更复杂的推理,在长对话中的上下文记忆也更加稳定。在数学、代码和通用推理等基准测试中,性能迅速逼近当时的国际顶尖模型,其中代码能力被认为可媲美Claude 4。
- V3.1 回答了“如何为未来硬件与复杂应用布局”的问题,并开始在混合推理架构和软硬件协同优化上进行关键布局
- 引入了混合推理架构,使得一个模型能同时支持需要快速响应的“即时模式”和需要深度思考的“思考模式”,更具适应性。采用FP8精度训练,能显著提升计算速度并降低存储需求。通过对模型进行后训练优化,其使用外部工具和执行复杂任务的能力(即Agent能力)获得了显著提升。
- V3.2 则回答了“如何在保持能力的同时,让AI变得真正便宜、好用且自主可控”的问题
- 引入了自研的DSA(DeepSeek Sparse Attention)稀疏注意力机制。该机制让模型在处理长文本时,能够智能地聚焦于最关键的信息,极大地提升了长文本的训练和推理效率。编程语言选用TileLang这个新兴AI编程语言,可以实现对不同硬件平台的支撑,极大地改善了国产卡目前所面对的CUDA带来的生态壁垒问题,为国产大模型软硬件生态建立起到了极大的推动作用。
Leaderboard [Update to Sep]
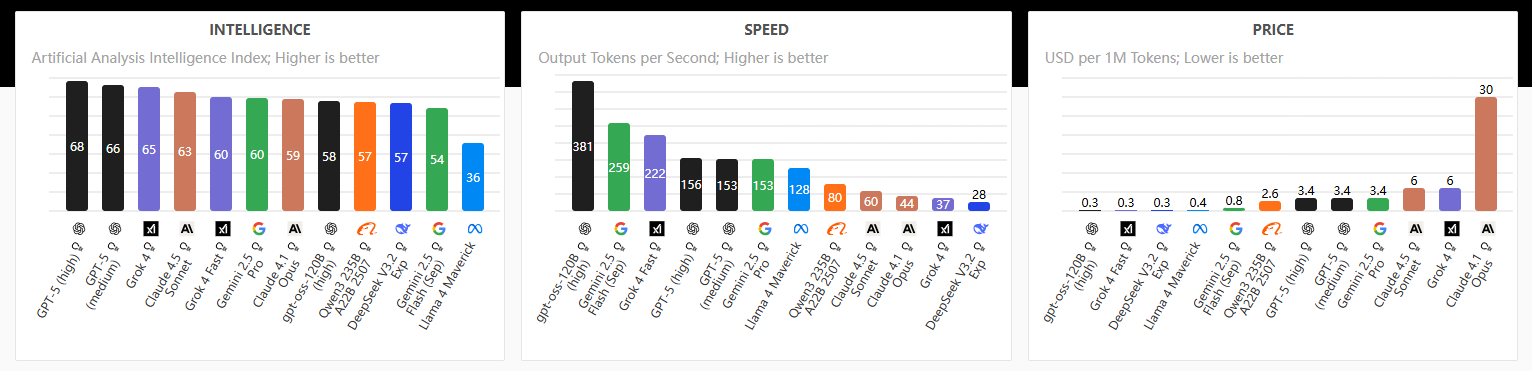
OpenAI 设计的榜单,涵盖了从对美国 GDP 贡献最大的 9 个行业中选出的 44 个职业,GDPval 任务并非简单的文本提示。它们附带参考文件和上下文,预期交付成果涵盖文档、幻灯片、图表、电子表格和多媒体。这种现实性使得 GDPval 能够更真实地测试模型如何支持专业人士。

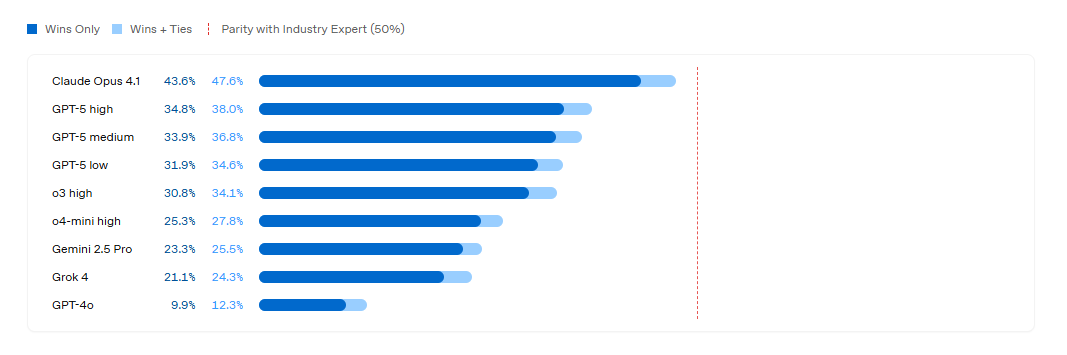
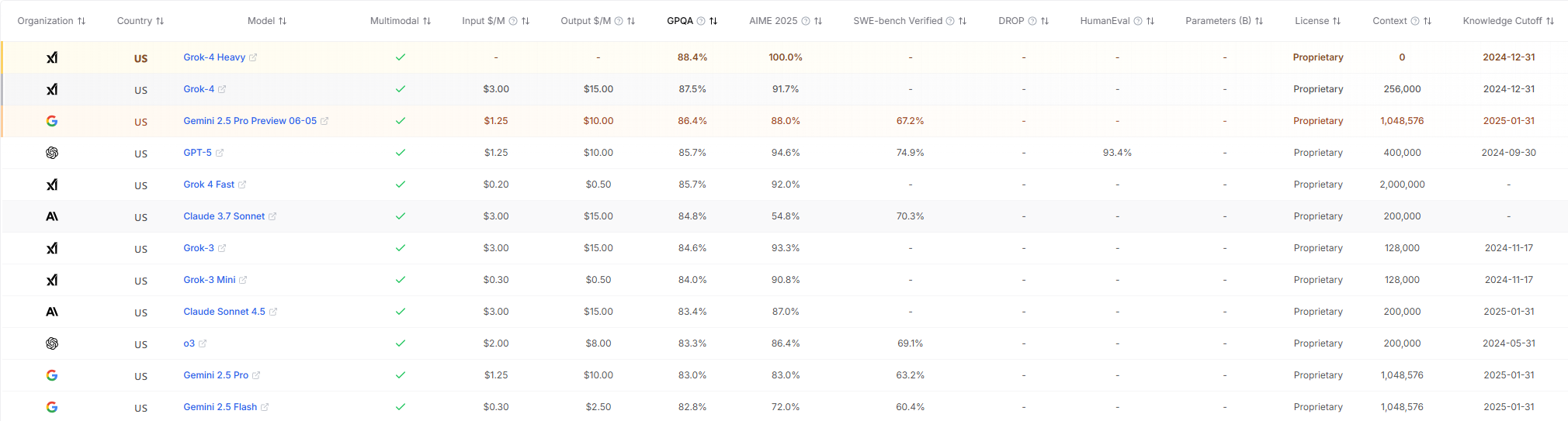
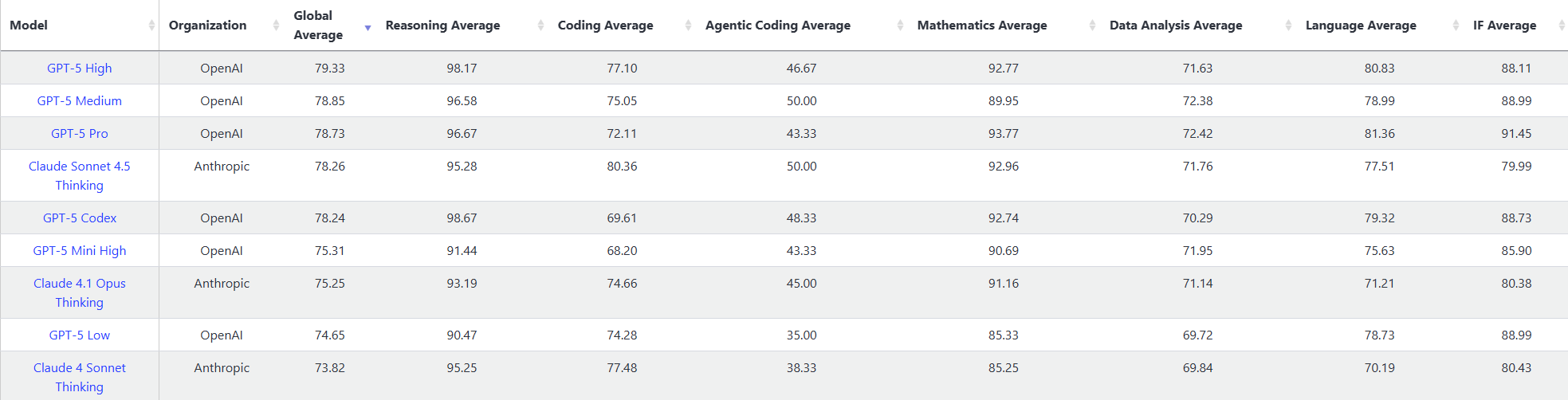
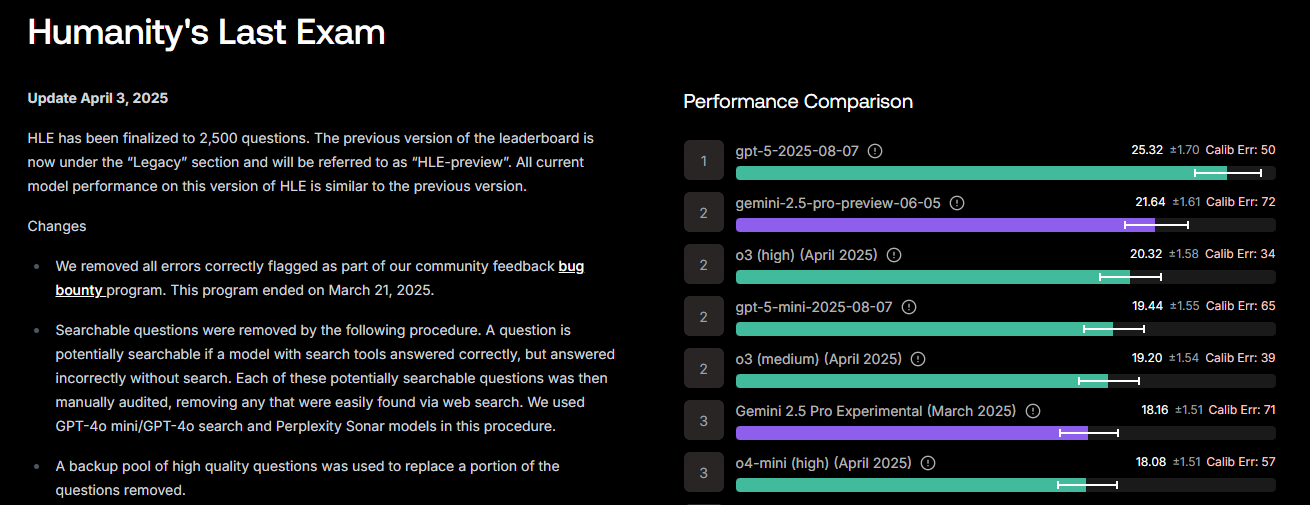
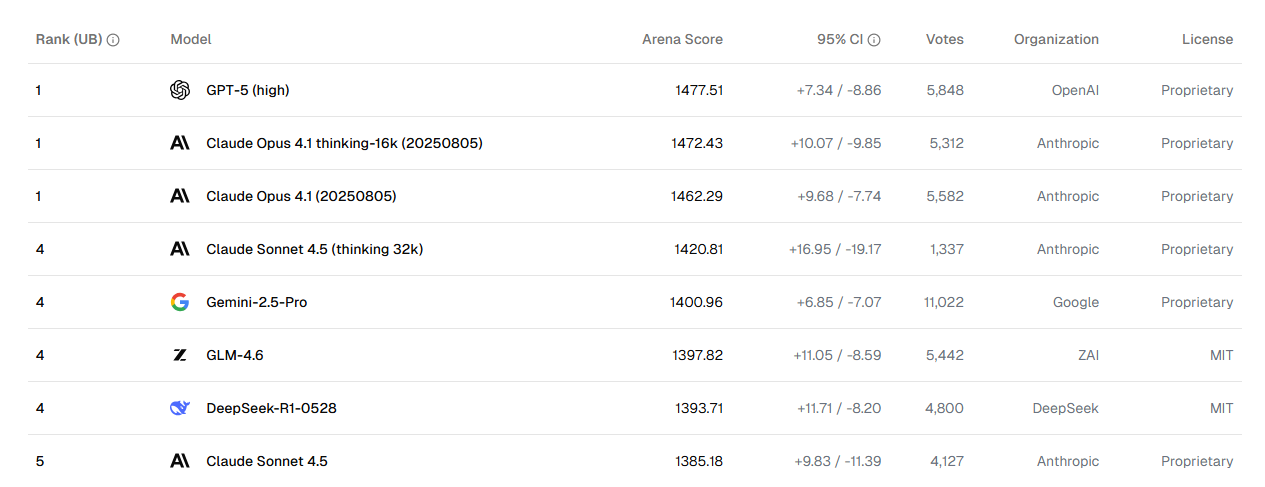
-
中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)是致力于科学、客观、中立的语言模型评测基准,发起于2019年。陆续推出CLUE、FewCLUE、KgCLUE、DataCLUE等广为引用的测评基准。
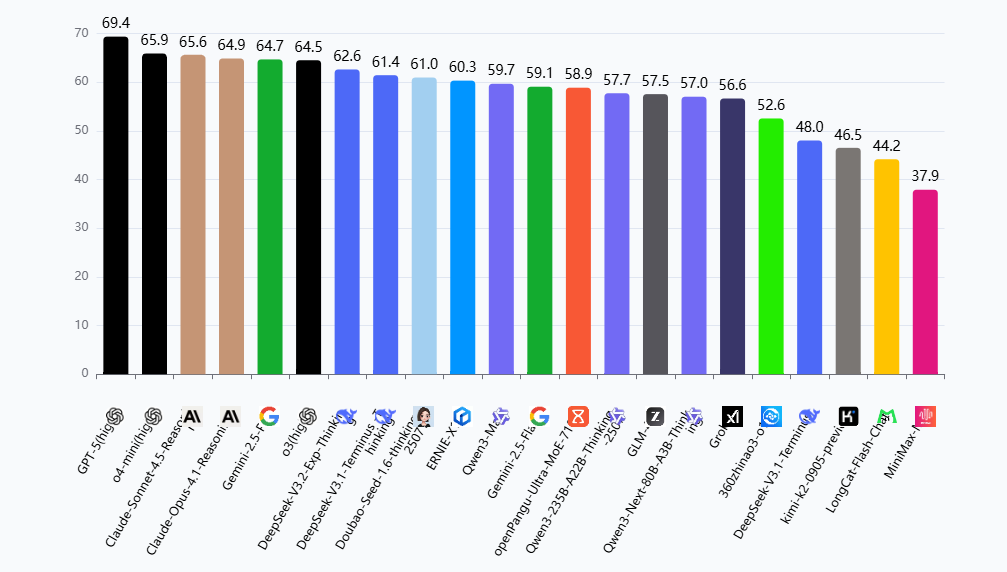
产业实证
实证结论
AI- First 公司与 SaaS 公司的早期增长:营收增长进入 “火箭” 模式
AI 企业达成关键营收里程碑的速度远超预期。Stripe 平台百强 AI 企业实现 100 万美元年化营收的中位用时仅为 11.5 个月,比营收增长最快的 SaaS 企业还快整整 4 个月。在达到 500 万美元年化营收时,AI 企业的中位用时为 24 个月,而 SaaS 企业则需 37 个月,AI 公司在此项上快了近一年。(Source: Stripe)
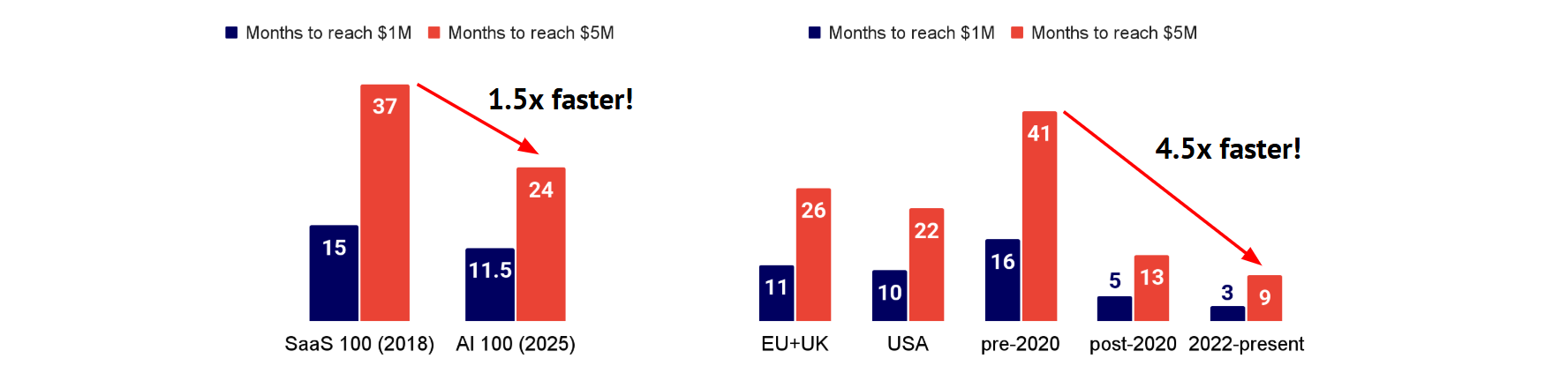
- TODO#AI-First 公司和 SaaS 公司的详细调研
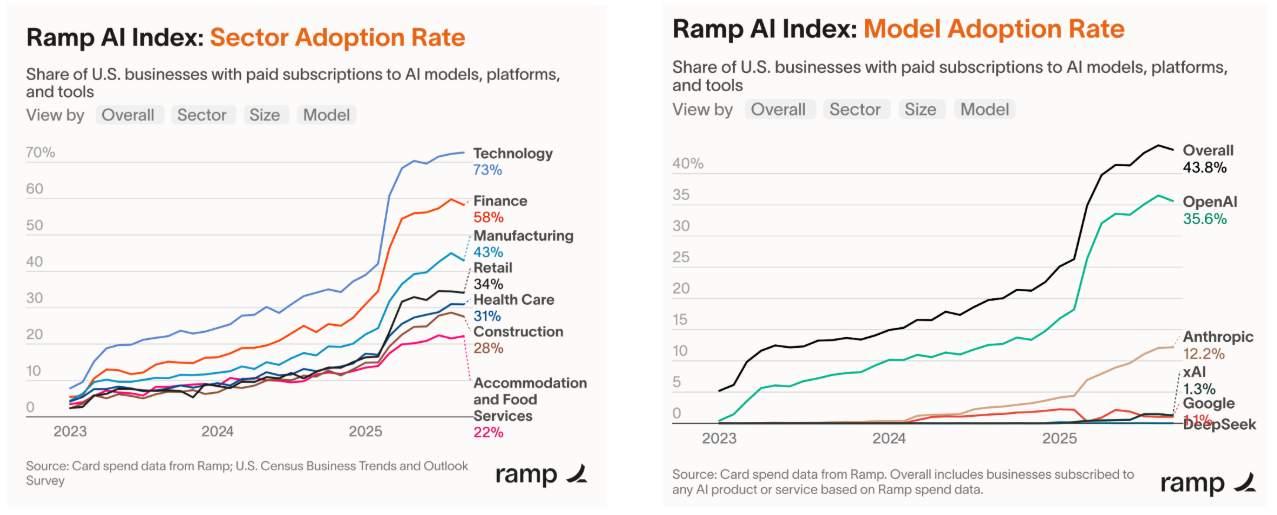
OpenAI 在应用的使用率上依旧断档领先
Ramp 的人工智能指数(来自 45,000 多家美国企业的信用卡 / 账单支付数据)显示,科技行业在付费人工智能采用率方面处于领先地位(73%),金融业紧随其后(58%)。总体而言,2025 年第一季度的采用率大幅上升。此外,Ramp 的客户对 OpenAI 模型表现出强烈的偏好(35.6%),其次是 Anthropic(12.2%)。与此同时,谷歌、深度求索(DeepSeek)和 xAI 的使用率非常低。
音频、虚拟形象和图像生成公司的收入出现了疯狂增长
市场领导者 ElevenLabs、Synthesia 和黑森林实验室(Black Forest Labs)的年收入都已轻松达到数亿美元。此外,由于收入来自企业客户以及超过 10 万名且不断增长的长尾客户,其收入质量正日益提高。
- ElevenLabs 在 9 个月内将年收入增长了一倍,达到 2 亿美元,并宣布其估值为 66 亿美元,与此同时还提出了 1 亿美元的员工股权收购要约。到 2026 年,客户已创建超过 200 万个智能体,这些智能体已处理超过 3300 万次对话。
- Source (ElevenLabs): https://elevenlabs.io/blog/introducing-elevenlabs-agents
- Synthesia 在 2025 年 4 月的年度经常性收入突破 1 亿美元,财富 100 强企业中有 70% 是其客户。自 2021 年推出以来(右侧图表),客户生成的虚拟形象视频时长已超过 3000 万分钟。
- 据悉,黑森林实验室(Black Forest Labs)的年度经常性收入约为 1 亿美元(同比增长 3.5 倍),毛利率为 78%,其中包括与 Meta 达成的一项为期两年、价值 1.4 亿美元的大额交易。此外,Midjourney 也与 Meta 达成了一项授权协议,但其条款尚未公开。
- Source (Black Forest Labs): https://x.com/ArfurRock/status/1965426792191439012
大模型作为答案引擎的风格化
这部分的研究结论主要来源于 Profound Data,大模型回答问题的风格,对搜索引擎的应用都会极大的影响用户体验,而这部分总体可以归结为问答引擎的风格化,风格会产生用户粘性。
- ChatGPT 用户平均每个会话有 5.6 轮对话,而 Gemini 和 Perplexity 约为 4 轮,DeepSeek 约为 3.9 轮。这要么意味着更多的轮次代表对话更具吸引力,要么意味着更少的轮次代表回答更高效
- 对话风格各不相同:DeepSeek 的用户会写出最长的提示词,并得到最冗长的回答,而 Perplexity 则会给出更简短、引用密集的回应。
- ChatGPT 通常会从人类通常不会点击的排名较低的页面中提取信息,这扩大了非顶级结果网站的曝光度。
- 各模型引用的顶级域名包括:Reddit(3.5%)、维基百科(1.7%)、YouTube(1.5%)和《福布斯》(1.0%)。
- 不同模型呈现出不同的信息来源风格:Gemini 和 Perplexity 倾向于主流的简洁信息来源,而 DeepSeek 则往往会从长篇内容的域名中获取信息
- 这意味着,针对答案引擎优化(AEO)进行优化与针对搜索引擎优化(SEO)同样重要,因为可见性不仅取决于排名,还取决于模型的引用模式。
推理和训练的盈亏平衡分析
推理为训练买单:实验室努力将模型生命周期计算中更多的部分分配给能带来收入的推理工作,且要尽可能追求最高的利润率。我们下方的表格 * 展示了在不同的推理利润率和计算分配情况下,计算成本的预期回报率。
- *Simplified sensitivity analysis: neglects people costs and assumes all inference generates revenue. Can also be interpreted in terms of token count between inference & training (2DN vs. 6DN, MFU: ~15% vs. ~45%).
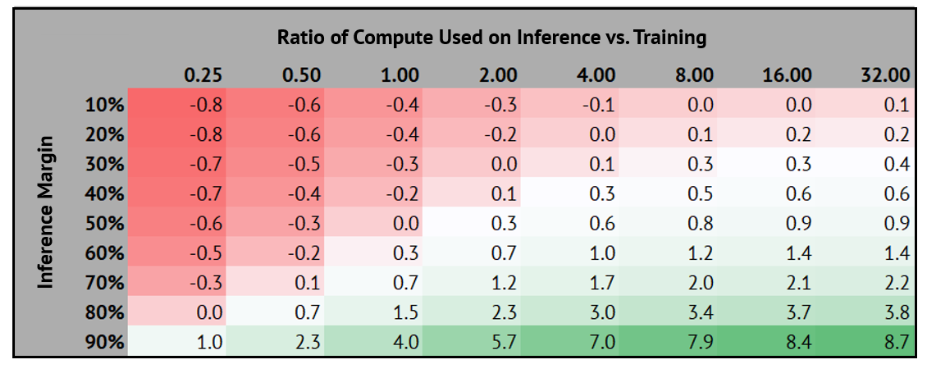
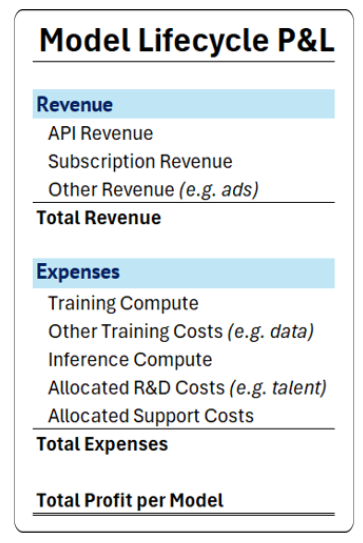
算力集群的建设军备竞赛
计划中约 1 吉瓦规模的集群将于 2026 年投入使用:在美国的实验室中,集群规模日益成为一个标志性特征,在招聘时尤其有用。如果估值依据的是集群规模而非采用率或财务指标,那么可能会形成一个更大的泡沫。
| Code Name | IT Power at YE 2026 | Number of Chips | Chip Type | Total TFLOPS | Provider |
|---|---|---|---|---|---|
| xAI - Colossus | 1,200 MW | GB200/300 | 550,000 | 3,488,148,649 | xAI |
| Meta - Promethus | 1,020 MW | GB200/300 | 500,000 | 3,171,044,226 | Meta |
| OpenAI - Stargate | 880 MW | GB200/300 | 400,000 | 2,469,594,595 | Oracle |
| Anthropic - Project Rainer | 780MW | Tranium 2 | 800,000 | 1,040,000,000 | AWS |
* 谷歌 DeepMind 也在爱荷华州、内布拉斯加州和俄亥俄州建立了许多值得关注的集群。但是谷歌的项目可获得的信息不足,并且是分布式的,所以并未列在上述表格中。
1GW 的 AI 数据中心盈利水平分析
资本支出,折旧与摊销,成本结构
NewStreet Research 给出了一个关于 1GW 数据中心的财务模型:500亿 CAPEX,110亿年总成本。
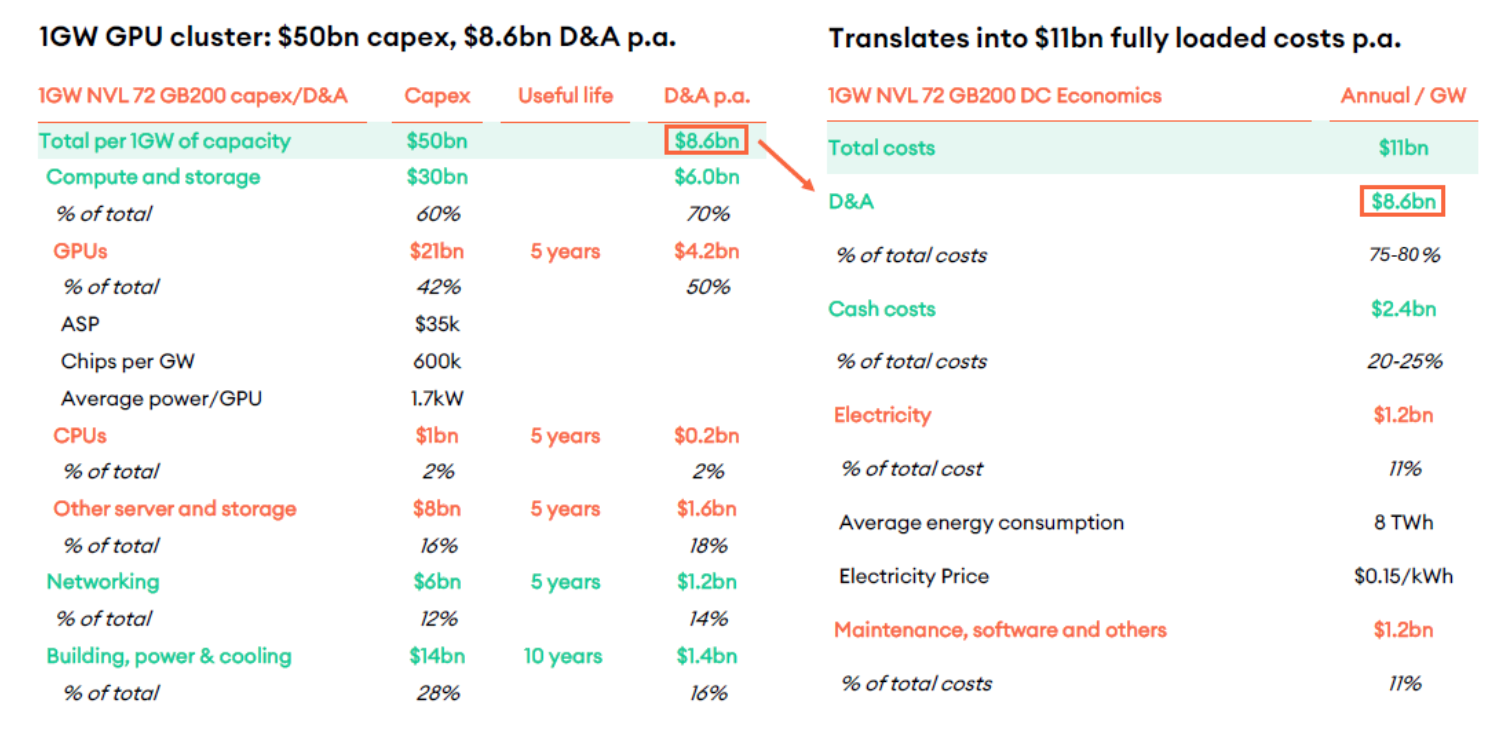
资本支出是建设数据中心的总投入,1GW AI 数据中心总 Capex 为 500 亿美元,具体构成如下:
- 计算与存储(Compute and storage):300 亿美元,占总 Capex 的 60%
- GPU:210 亿美元(占总 Capex 的 42%),是核心硬件成本。每 GW 需要 60 万块芯片,单块 GPU 平均售价(ASP)3.5 万美元,单 GPU 平均功耗 1.7kW。
- CPU:10 亿美元(占 2%)。
- 其他服务器和存储:80 亿美元(占 16%)。
- 网络(Networking):60 亿美元,占总 Capex 的 12%。
- 建筑、电力与冷却(Building, power & cooling):140 亿美元,占总 Capex 的 28%,是支撑算力运行的基础设施成本。
D&A 是将资本支出在资产使用寿命内逐年分摊的费用,直接影响年度成本结构:
- 不同资产的使用寿命决定了 D&A 的年限:GPU、CPU、其他服务器存储、网络设备:使用寿命 5 年。建筑、电力与冷却设施:使用寿命 10 年。
- 年度 D&A 总额为 86 亿美元($8.6bn p.a.),具体拆分:
- GPU:42 亿美元 / 年(210 亿 ÷ 5 年),占总 D&A 的 50%。
- CPU:2 亿美元 / 年(10 亿 ÷ 5 年),占 2%。
- 其他服务器和存储:16 亿美元 / 年(80 亿 ÷ 5 年),占 18%。
- 网络:12 亿美元 / 年(60 亿 ÷ 5 年),占 14%。
- 建筑、电力与冷却:14 亿美元 / 年(140 亿 ÷10 年),占 16%。
年度全部成本为110 亿美元($11bn p.a.),由 “D&A” 和 “现金成本(Cash Costs)” 组成:
- D&A 占比 75 - 80%:86 亿美元 / 年,是最主要的年度成本,反映了资产折旧对利润的持续压力。
- 现金成本占比 20 - 25%:24 亿美元 / 年,具体拆分:
- 电力:12 亿美元 / 年(占总成本的 11%)。年均能耗 8TWh,电价 $0.15/kWh(计算:8TWh×$0.15/kWh = $1.2bn)。
- 维护、软件及其他:12 亿美元 / 年(占总成本的 11%)。
数据中心盈利水平分析(以 Oracle & OpenAI 的合作为例)
虽然目前公开信息还无法精确计算出甲骨文在此笔交易中的最终盈利,但我们可以根据现有数据,对其盈利水平和财务模型进行一次深入的推演分析。下面这个表格梳理了与本次交易相关的一些关键已知数据和合理的估算参数,可以作为我们分析的基础。
| 项目 | 数据/估算 |
|---|---|
| 合同规模 | 4.5 GW (总计) |
| 年度费用 | 300亿美元 |
| 硬件投资估算 | ~400亿美元 (以阿比林1.2GW园区为例,部署约40万GPU) |
| 甲骨文官方毛利率指引 | 30% - 40% (AI基础设施,扣除土地、数据中心、电力和计算设备成本后) |
- 收入端:主要来自OpenAI支付的300亿美元/年的巨额租金。
- 成本端:主要包含以下几大块:
- 硬件折旧:这是最大头的成本。根据的分析,一个类似的GPU数据中心项目中,服务器折旧是成本中绝对的大头。如果4.5GW的总投资按数百亿美元计算,其每年的折旧费用将非常惊人。
- 电力成本:1GW的数据中心年耗电量约为8 TWh,电费约12亿美元。4.5GW的规模,年电费成本预计超过50亿美元。
- 托管与运维成本:包括场地租金、网络、冷却和维护等。在的模型中,这项与电费成本相加,年支出约20亿美元(针对较小规模)。
- 融资成本:如此大规模的投资,甲骨文很可能通过借款进行,由此产生的利息费用也是一笔不小的开支。
SemiAnalysis 针对这份交易也给出了一个盈利分析,以 40W 块 GB200 的数据中心来进行预测:
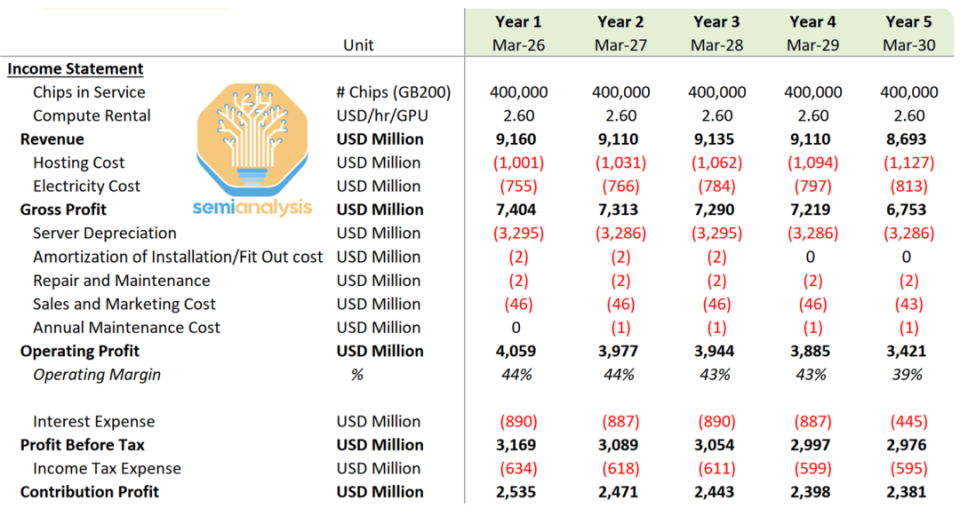
基础指标
- Chips in Service(在用芯片数量):每年稳定在 400,000 块(GB200 芯片)。
- Compute Rental(算力租赁单价):2.60 USD/hr/GPU,是算力服务的单位定价,为收入核算的基础。
收入端:算力租赁业务的规模与稳定性
- Revenue(营业收入):年营收在86.93 亿–91.60 亿美元区间,整体保持高位且小幅波动。
- 说明 “算力租赁” 是核心收入来源,市场需求稳定,具备较强的营收持续性。
成本端:构成与变化逻辑
(1)直接成本(影响毛利)
- Hosting Cost(托管成本):年支出10.01 亿 – 12.27 亿美元,逐年上升。
- 反映算力集群的托管运维复杂度增加(如场地、基础服务外包成本上升)。
- Electricity Cost(电力成本):年支出7.55 亿 – 8.13 亿美元,逐年上升。
- 是算力运行的核心可变成本,与芯片规模、电价波动或能效优化节奏有关(按芯片数量比例换算,与前 1GW 模型的电力成本逻辑完全匹配)。
(2)固定成本(影响运营利润)
- Server Depreciation(服务器折旧):年支出32.86 亿 – 32.95 亿美元,几乎无波动。
- 源于服务器类资产的 “年限平均法” 折旧(资产使用寿命固定),是核心固定成本。
- Amortization of Installation/Fit Out cost(安装 / 装修成本摊销):前 3 年每年 2 亿美元,第 4-5 年为 0。
- 此类资产(如机房装修、专项安装工程)摊销年限为 3 年,到期后不再产生摊销成本。
- Repair and Maintenance(维修维护成本):每年 2 亿美元,固定支出。
- 保障服务器、设施的正常运行,属于常规运维成本。
- Sales and Marketing Cost(销售与营销成本):前 4 年每年 4.6 亿美元,第 5 年 4.3 亿美元。
- 前期为拓展市场投入营销资源,后期业务成熟后小幅缩减,属于合理的费用优化。
- Annual Maintenance Cost(年度维护成本):第 2-5 年每年 1 亿美元(第 1 年无)。
- 可能是新增长期维护合同或设备老化后专项维护的支出,体现运维策略的阶段性调整。
四、盈利端:高毛利与持续盈利性
- Gross Profit(毛利):67.53 亿 – 74.04 亿美元,毛利规模大且支撑力强。
- 毛利 = 收入 - 托管成本 - 电力成本,反映 “算力租赁” 业务的核心盈利能力。
- Operating Profit(运营利润):34.21 亿 – 40.59 亿美元,运营效率突出。
- 运营利润 = 毛利 - 各类运营成本(折旧、摊销、维修、营销、维护),体现扣除所有运营成本后的盈利水平。
- Operating Margin(运营利润率):39% – 44%,属于高毛利行业的典型表现。
- 说明业务模式的盈利能力极强,成本管控与收入规模的协同效应显著。
- Interest Expense(利息支出):前 4 年每年8.87 亿 – 8.90 亿美元,第 5 年降至 4.45 亿美元。
- 前期因资本投入产生较高债务利息,第 5 年或因债务偿还、利率调整而大幅下降。
- Profit Before Tax(税前利润):29.76 亿 – 31.69 亿美元,是运营利润扣除利息后的盈利。
- Income Tax Expense(所得税费用):5.95 亿 – 6.34 亿美元,税率约 20%(所得税 / 税前利润),符合企业所得税常规水平。
- Contribution Profit(税后利润,实际为净利润):23.81 亿 – 25.35 亿美元,每年稳定创造 20 多亿美元税后利润。
- 反映业务在覆盖所有成本(运营 + 财务 + 税务)后,具备持续的盈利产出能力。
Reference
Wu, Yangzhen, et al. “Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models.” arXiv preprint arXiv:2408.00724 (2024).
Pilz, Konstantin F., et al. “Trends in AI supercomputers.” arXiv preprint arXiv:2504.16026 (2025).
Liu, Aixin, et al. “Deepseek-v3 technical report.” arXiv preprint arXiv:2412.19437 (2024).
State of AI 2025
http://vincentgaohj.github.io/Blog/2025/09/24/State-of-AI-2025/