Not Enough Data? Deep Learning to the Rescue!
What a data scientist to do if they lack sufficient data or suffer from extreme imbalanced dataset to train a deep learning model?
The answer definitely is using IBM’s Lambada AI generates training data for text classifiers. Here is an full implementation of the paper ‘Not Enough Data? Deep Learning to the Rescue!‘ with code.
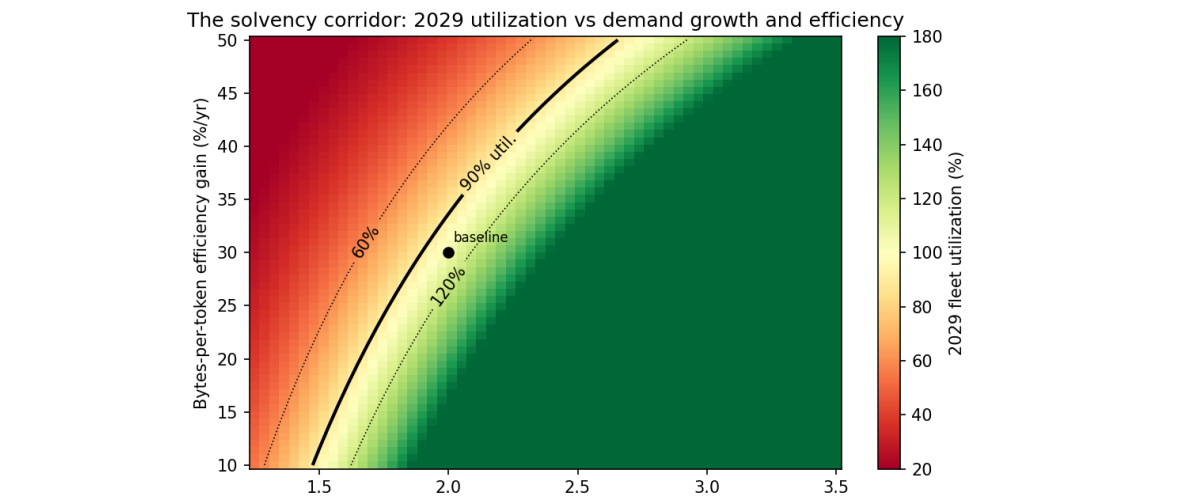
LAMBADA AI method overview
An interesting approach to generate training utterances called LAMBADA (language-model-based data augmentation) has been published by IBM Research AI.
The underlying idea is to take a language model, which has been pretrained on large corpora such as Wikipedia and books, that is able to generate textual output of good quality. This language model is then fine-tuned on the available domain specific data. After fine-tuning, the model can then be used to generate additional utterances. These utterances in turn improve the training of Intent Classification models.
Reference
Scientific Paper
Blog
Not Enough Data? Deep Learning to the Rescue!
http://vincentgaohj.github.io/Blog/2021/10/26/Not-Enough-Data-Deep-Learning-to-the-Rescue/