Build Modern Serverless Applications with AWS Amplify and AppSync
In the fast-paced field of web applications, containerization has become not only common but the preferred mode of packaging and delivering web applications. Containers allow us to package our applications and deploy them anywhere without having to reconfigure or adapt our applications to the deployment platform.
Amazon Elastic Container Service (Amazon ECS) is the service Amazon provide to run Docker applications on a scalable cluster.

AWS Amplify
AWS Amplify is a set of products and tools that enable mobile and front-end web developers to build and deploy secure, scalable full-stack applications, powered by AWS.
Common Command Line
amplify <category> <subcommand>amplify <category> add: Add resources of a category to the cloud.- Place a CloudFormation template for the resources of this category in the category’s subdirectory
amplify/backend/\<category\> - Insert its reference into the above-mentioned root stack as the nested child stack.
- When working in teams, it is good practice to run an
amplify pullbefore modifying the backend categories.
- Place a CloudFormation template for the resources of this category in the category’s subdirectory
amplify <category> updateamplify <category> removeamplify <category> push
amplify push: Once you have made your category updates, run the commandamplify pushto update the cloud resources.amplify pull: Operates similar to a git pull.amplify env <subcommand>: Control multiple environmentamplify env addamplify env listamplify env checkoutamplify env remove
amplify console: Launches the browser directing you to your cloud project in the AWS Amplify Console.amplify deleteamplify init: the root stack is created with three resources:- IAM role for unauthenticated users
- IAM role for authenticated users
- S3 bucket, the deployment bucket, to support this provider’s workflow
amplify publishamplify runamplify status
Amplify CLI
The Amplify Command Line Interface (CLI) is a unified tool-chain to create, integrate, and manage the AWS cloud services for your app.
- **Authentication: **The Amplify CLI supports configuring many different Authentication and Authorization workflows, including simple and advanced configurations of the login options, triggering Lambda functions during different lifecycle events, and administrative actions which you can optionally expose to your applications.
- **API(GraphQL): **The GraphQL Transform provides a simple to use abstraction that helps you quickly create backends for your web and mobile applications on AWS. With the GraphQL Transform, you define your application’s data model using the GraphQL Schema Definition Language (SDL) and the library handles converting your SDL definition into a set of fully descriptive AWS CloudFormation templates that implement your data model.
- **Serverless Functions: **You can add a Lambda function to your project which you can use alongside a REST API or as a data source in your GraphQL API using the
@functiondirective. - **Storage: **Amplify CLI’s
storagecategory enables you to create and manage cloud-connected file & data storage. Use thestoragecategory when you need to store:- app content (images, audio, video etc.) in an public, protected or private storage bucket or
- app data in a NoSQL database and access it with a REST API + Lambda
Directives
The Amplify CLI provides GraphQL directives to enhance your schema with additional capabilities, such as custom indexes, authorization rules, function triggers and more.
@model: Defines a top level object type in your API that are backed by Amazon DynamoDB
Allows you to easily define top level object types in your API that are backed by Amazon DynamoDB.
1
2
3
4
5
6# override the names of any generated queries, mutations and subscriptions, or remove operations entirely.
type Post @model(queries: { get: "post" }, mutations: null, subscriptions: null) {
id: ID! # id: ID! is a required attribute.
title: String!
tags: [String!]!
}
@key: Configures custom index structures for @model types
The
@keydirective makes it simple to configure custom index structures for@modeltypes.1
directive @key(fields: [String!]!, name: String, queryField: String) on OBJECT
A
@keywithout a name specifies the key for the DynamoDB table’s primary index. You may only provide 1@keywithout a name per@modeltype.Argument
fields- The first field in the list will always be the HASH key.
- If two fields are provided the second field will be the SORT key.
- If more than two fields are provided, a single composite SORT key will be created from a combination of
fields[1...n].
name- When provided, specifies the name of the secondary index.
- When omitted, specifies that the
@keyis defining the primary index.
queryField- When defining a secondary index (by specifying the name argument), this specifies that a new top level query field that queries the secondary index should be generated with the given name.
Using the new ‘todosByStatus’ query you can fetch todos by ‘status’
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16type Todo @model
@key(name: "todosByStatus", fields: ["status"], queryField: "todosByStatus") {
id: ID!
name: String!
status: String!
}
query todosByStatus {
todosByStatus(status: "completed") {
items {
id
name
status
}
}
}
@auth: Defines authorization rules for your @model types and fields
Authorization is required for applications to interact with your GraphQL API. API Keys are best used for public APIs (or parts of your schema which you wish to be public) or prototyping, and you must specify the expiration time before deploying.
When applied to a type, augments the application with owner and group-based authorization rules.
1
2
3
4
5
6
7
8
9
10directive @auth(rules: [AuthRule!]!) on OBJECT | FIELD_DEFINITION
input AuthRule {
allow: AuthStrategy!
provider: AuthProvider
ownerField: String # defaults to "owner" when using owner auth
identityClaim: String # defaults to "username" when using owner auth
groupClaim: String # defaults to "cognito:groups" when using Group auth
groups: [String] # Required when using Static Group auth
groupsField: String # defaults to "groups" when using Dynamic Group auth
operations: [ModelOperation] # Required for finer controlonly the owner of the object has the authorization to perform read (
getTodoandlistTodos), update (updateTodo), and delete (deleteTodo) operations on the owner created object1
2
3
4
5
6type Todo @model
@auth(rules: [{ allow: owner }]) {
id: ID!
updatedAt: AWSDateTime!
content: String!
}only the owner of the object has the authorization to perform update (
updateTodo) and delete (deleteTodo) operations on the owner created object, but anyone can read them (getTodo,listTodos).1
2
3
4
5
6type Todo @model
@auth(rules: [{ allow: owner, operations: [create, delete, update] }]) {
id: ID!
updatedAt: AWSDateTime!
content: String!
}
@connection: Defines 1:1, 1:M, and N:M relationships between @model types
Has one: In the simplest case, you can define a one-to-one connection where a project has one team:
1
2
3
4
5
6
7
8
9
10type Project @model {
id: ID!
name: String
team: Team @connection
}
type Team @model {
id: ID!
name: String!
}Has many: The following schema defines a Post that can have many comments:
1
2
3
4
5
6
7
8
9
10
11
12type Post @model {
id: ID!
title: String!
comments: [Comment] @connection(keyName: "byPost", fields: ["id"])
}
type Comment @model
@key(name: "byPost", fields: ["postID", "content"]) {
id: ID!
postID: ID!
content: String!
}
@function: Configures a Lambda function resolvers for a field
The
@functiondirective allows you to quickly & easily configure AWS Lambda resolvers within your AWS AppSync API.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18directive @function(name: String!, region: String) on FIELD_DEFINITION
# You can connect this function to your AppSync API deployed via Amplify using this schema:
# Using this as the entry point, you can use a single function to handle many resolvers.
type Query {
posts: [Post] @function(name: "GraphQLResolverFunction")
}
type Post {
id: ID!
title: String!
comments: [Comment] @function(name: "GraphQLResolverFunction")
}
type Comment {
postId: ID!
content: String
}
@http: Configures an HTTP resolver for a field
The
@httpdirective allows you to quickly configure HTTP resolvers within your AWS AppSync API.1
2
3
4
5
6directive @http(method: HttpMethod, url: String!, headers: [HttpHeader]) on FIELD_DEFINITION
enum HttpMethod { PUT POST GET DELETE PATCH }
input HttpHeader {
key: String
value: String
}The directive allows you to define URL path parameters, and specify a query string and/or specify a request body.
1
2
3
4
5
6
7
8
9
10type Post {
id: ID!
title: String
description: String
views: Int
}
type Query {
listPosts: Post @http(url: "https://www.example.com/posts")
}
The
@predictionsdirective allows you to query an orchestration of AI/ML services such as Amazon Rekognition, Amazon Translate, and/or Amazon Polly.1
2
3
4
5
6
7directive @predictions(actions: [PredictionsActions!]!) on FIELD_DEFINITION
enum PredictionsActions {
identifyText # uses Amazon Rekognition to detect text
identifyLabels # uses Amazon Rekognition to detect labels
convertTextToSpeech # uses Amazon Polly in a lambda to output a presigned url to synthesized speech
translateText # uses Amazon Translate to translate text from source to target language
}
@searchable: Makes your data searchable by streaming it to Elasticsearch
The
@searchabledirective handles streaming the data of an@modelobject type to Amazon Elasticsearch Service and configures search resolvers that search that information.1
2
3# Streams data from DynamoDB to Elasticsearch and exposes search capabilities.
directive @searchable(queries: SearchableQueryMap) on OBJECT
input SearchableQueryMap { search: String }
@versioned: Defines the versioning and conflict resolution strategy for an @model type
The
@versioneddirective adds object versioning and conflict resolution to a type. Do not use this directive when leveraging DataStore as the conflict detection and resolution features are automatically handled inside AppSync and are incompatible with the@versioneddirective.1
directive @versioned(versionField: String = "version", versionInput: String = "expectedVersion") on OBJECT
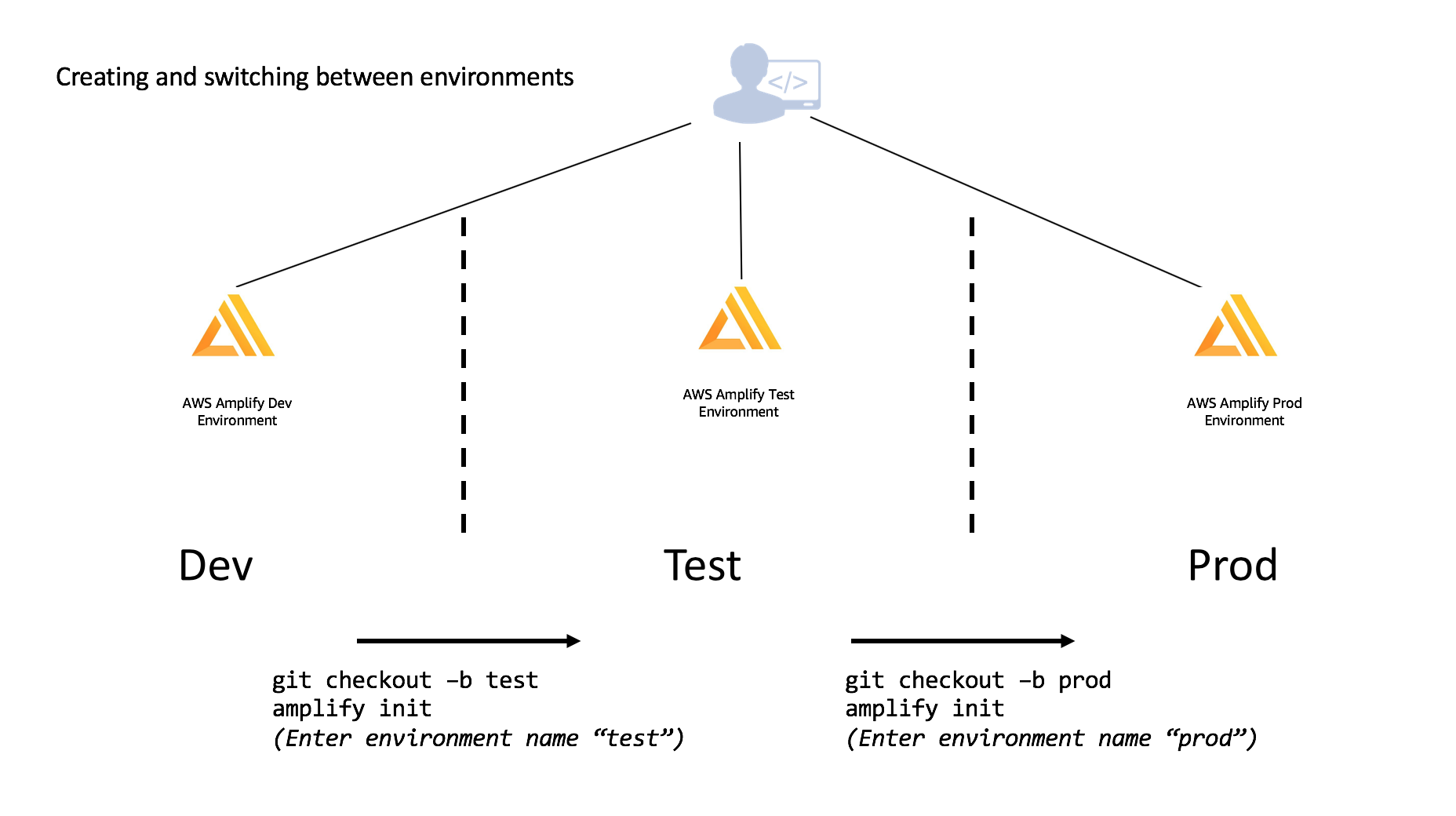
Team Environment
For multiple environments, Amplify matches the standard Git workflow where you switch between different branches using the env checkout command - similar to running git checkout BRANCHNAME, run amplify env checkout ENVIRONMENT_NAME to switch between environments.
Modeling Relational Data in DynamoDB
Data access patterns
1 | type Order @model |
AWS Lambda in Python
Lambda deployment packages
Your AWS Lambda function’s code consists of scripts or compiled programs and their dependencies. You use a deployment package to deploy your function code to Lambda. Lambda supports two types of deployment packages: container images and .zip files.
.zip file archives
Using other AWS services to build a deployment package
Build Modern Serverless Applications with AWS Amplify and AppSync