Apache Spark: the New ‘king’ of Big Data

[TOC]
About
What is Hadoop?
It’s a general-purpose form of distributed processing that has several components:
- HDFS(The Hadoop Distributed File System), which stores files in a Hadoop-native format and parallelizes them across a cluster;
- YARN, a schedule that coordinates application runtimes;
- MapReduce, the algorithm that actually processes the data in parallel.
Hadoop is built in Java, and accessible through many programming languages, for writing MapReduce code, including Python, through a Thrift client.
What is Apache Spark?
Spark as a whole consists of various libraries, APIs, databases, etc. The main components of Apache Spark are as follows:
**Spark Core: **Spare Core is the basic building block of Spark, which includes all components for job scheduling, performing various memory operations, fault tolerance, and more. Spark Core is also home to the API that consists of RDD. Moreover, Spark Core provides APIs for building and manipulating data in RDD.
**Spark SQL: **Apache Spark works with the unstructured data using its ‘go to’ tool, Spark SQL. Spark SQL allows querying data via SQL, as well as via Apache Hive’s form of SQL called Hive Query Language (HQL). It also supports data from various sources like parse tables, log files, JSON, etc. Spark SQL allows programmers to combine SQL queries with programmable changes or manipulations supported by RDD in Python, Java, Scala, and R.
**Spark Streaming: **Spark Streaming processes live streams of data. Data generated by various sources is processed at the very instant by Spark Streaming. Examples of this data include log files, messages containing status updates posted by users, etc.
**GraphX: **GraphX is Apache Spark’s library for enhancing graphs and enabling graph-parallel computation. Apache Spark includes a number of graph algorithms which help users in simplifying graph analytics.
**MLlib: **Apache Spark comes up with a library containing common Machine Learning (ML) services called MLlib. It provides various types of ML algorithms including regression, clustering, and classification, which can perform various operations on data to get meaningful insights out of it.
Spark has several APIs. The original interface was written in Scala, and based on heavy usage by data scientists, Python and R endpoints were also added. Java is another option for writing Spark jobs.
Apache Spark vs Hadoop vs Hive
That’s not to say Hadoop is obsolete. It does things that Spark does not, and often provides the framework upon which Spark works. The Hadoop Distributed File System enables the service to store and index files, serving as a virtual data infrastructure.
Spark, on the other hand, performs distributed, high-speed compute functions on that architecture. If Hadoop is the professional kitchen with the tools and equipment to build and cook meals of data, then Spark is the expediter that rapidly assembles and distributes those meals for consumption.
Because Spark was built to work with and run on the Hadoop infrastructure, the two systems work well together. Fast-growing organizations built in Hadoop can easily add Spark’s speed and functionality as needed.
As for the different between hive and Spark, they are different products built for different purposes in the big data space. Hive is a distributed database, and Spark is a framework for data analytics.
Hive is a pure data warehousing database which stores data in the form of tables. As a result, it can only process structured data read and written using SQL queries. Hive is not an option for unstructured data. In addition, Hive is not an ideal for OLTP or OLAP kinds of operations.
Key Terminology and Concepts
- Spark RDDs
- Resilient Distributed Datasets are data structures that are the core building blocks of Spark. A RDD is an immutable, partitioned collection of records, which means that it can hold values, tuples, or other objects, these records are partitioned so as to be processed on a distributed system, and that once an RDD has been made, it is impossible to alter it.
- Spark DataFrame have all of the features of RDDs but also have a schema. This will make them our data structure of choice for getting started with PySpark.
- Spark DataSets are similar to DataFrames but are strongly-typed, meaning that the type is specified upon the creation of the DataSet and is not inferred from the type of records stored in it. This means DataSets are not used in PySpark because Python is a dynamically-typed language.
- Transformations
- Transformations are one of the things you can do to an RDD in Spark.
- Transformations take an RDD as an input and perform some function on them based on what Transformation is being called, and outputs one or more RDDs.
- Actions
- An Action is any RDD operation that does not produce an RDD as an output.
- Aan Action is the cue to the compiler to evaluate the lineage graph and return the value specified by the Action.
- Lineage Graph
- A lineage graph outlines what is called a “logical execution plan”. What that means is that the compiler begins with the earliest RDDs that aren’t dependent on any other RDDs, and follows a logical chain of Transformations until it ends with the RDD that an Action is called on.
- This feature is primarily what drives Spark’s fault tolerance. If a node fails for some reason, all the information about what that node was supposed to be doing is stored in the lineage graph, which can be replicated elsewhere.
- Application
- A Spark application is a user built program that consists of a driver and that driver’s associated executors.
- Job
- A Spark job is task or set of tasks to be executed with executor processes, as directed by the driver.
- A job is triggered by the calling of an RDD Action.
- Map Stage in Map Reduce
- The map or mapper’s job is to process the input data. Generally the input data is in the form of file or directory and is stored in the Hadoop file system (HDFS).
- The input file is passed to the mapper function line by line. The mapper processes the data and creates several small chunks of data.
- Reduce Stage in Map Reduce
- This stage is the combination of the Shuffle stage and the Reduce stage.
- The Reducer’s job is to process the data that comes from the mapper. After processing, it produces a new set of output, which will be stored in the HDFS.
Apache Spark Architecture
Features of Apache Spark
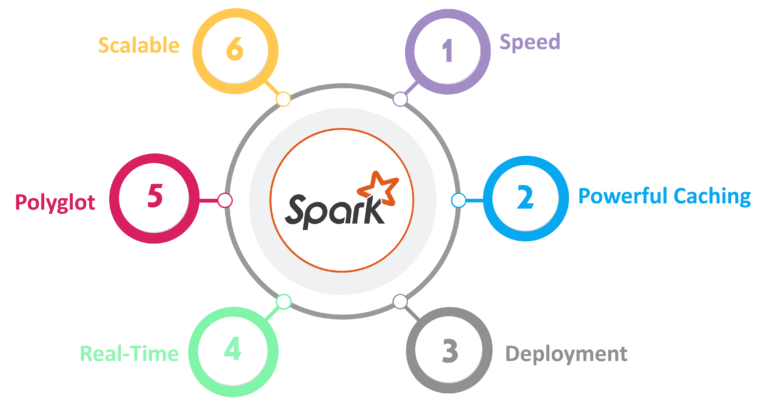
- Speed
Spark runs up to 100 times faster than Hadoop MapReduce for large-scale data processing. It is also able to achieve this speed through controlled partitioning.
Powerful Caching
Simple programming layer provides powerful caching and disk persistence capabilities.
Deployment
It can be deployed through Mesos, Hadoop via YARN, or Spark’s own cluster manager.
Real-Time
It offers Real-time computation & low latency because of in-memory computation.Polyglot
Spark provides high-level APIs in Java, Scala, Python, and R. Spark code can be written in any of these four languages. It also provides a shell in Scala and Python.
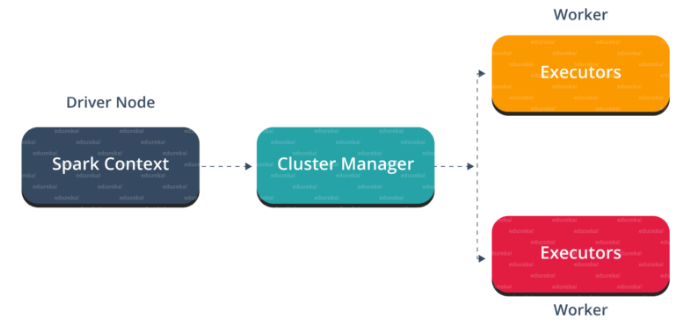
Spark Architecture Overview
Apache Spark has a well-defined layered architecture where all the spark components and layers are loosely coupled. This architecture is further integrated with various extensions and libraries. Apache Spark Architecture is based on two main abstractions:
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
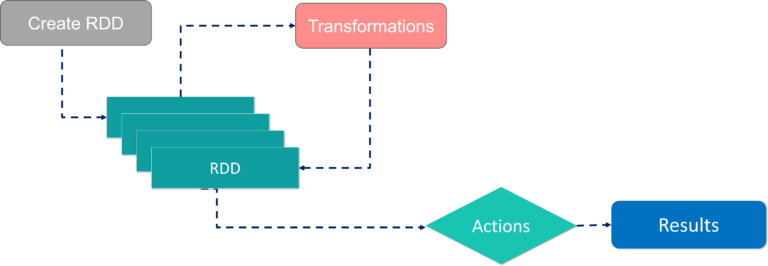
Resilient Distributed Dataset(RDD)
RDDs are the building blocks of any Spark application. RDDs Stands for:
- Resilient: Fault tolerant and is capable of rebuilding data on failure
- Distributed: Distributed data among the multiple nodes in a cluster
- Dataset: Collection of partitioned data with values
Using Hadoop and Spark together
There are several instances where you would want to use the two tools together. Despite some asking if Spark will replace Hadoop entirely because of the former’s processing power, they are meant to complement each other rather than compete. Below you can see a simplified version of Spark-and-Hadoop architecture:

Hadoop can—at a lower price—deal with heavier operations while Spark processes the more numerous smaller jobs that need instantaneous turnaround.
YARN also makes archiving and analysis of archived data possible, whereas it isn’t with Apache Spark. Thus, Hadoop and YARN in particular becomes a critical thread for tying together the real-time processing, machine learning and reiterated graph processing.
Summing it up
So is it Hadoop or Spark? These systems are two of the most prominent distributed systems for processing data on the market today. Hadoop is used mainly for disk-heavy operations with the MapReduce paradigm, and Spark is a more flexible, but more costly in-memory processing architecture. Both are Apache top-level projects, are often used together, and have similarities, but it’s important to understand the features of each when deciding to implement them.
So is it Spark or Hive? Hive and Spark are both immensely popular tools in the big data world. Hive is the best option for performing data analytics on large volumes of data using SQLs. Spark, on the other hand, is the best option for running big data analytics. It provides a faster, more modern alternative to MapReduce.
ML Pipelines
ML Pipelines provide a uniform set of high-level APIs built on top of DataFrames that help users create and tune practical machine learning pipelines.
Main concepts in Pipelines
DataFrame: This ML API usesDataFramefrom Spark SQL as an ML dataset, which can hold a variety of data types. E.g., aDataFramecould have different columns storing text, feature vectors, true labels, and predictions.Transformer: ATransformeris an algorithm which can transform oneDataFrameinto anotherDataFrame. E.g., an ML model is aTransformerwhich transforms aDataFramewith features into aDataFramewith predictions.Estimator: AnEstimatoris an algorithm which can be fit on aDataFrameto produce aTransformer. E.g., a learning algorithm is anEstimatorwhich trains on aDataFrameand produces a model.Pipeline: APipelinechains multipleTransformers andEstimators together to specify an ML workflow.Parameter: AllTransformers andEstimators now share a common API for specifying parameters.
How it works
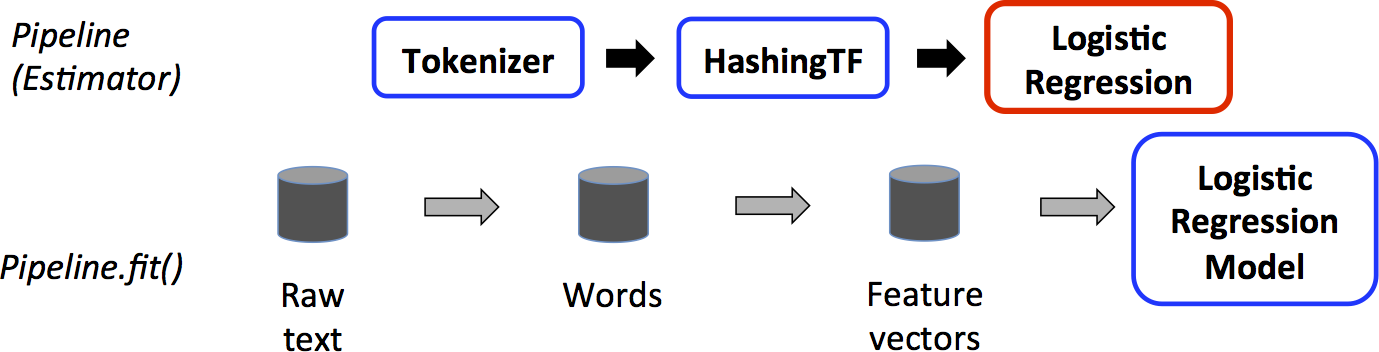
- The first two (
TokenizerandHashingTF) areTransformers (blue), and the third (LogisticRegression) is anEstimator(red). The bottom row represents data flowing through the pipeline, where cylinders indicateDataFrames. - The
Pipeline.fit()method is called on the originalDataFrame, which has raw text documents and labels. - The
Tokenizer.transform()method splits the raw text documents into words, adding a new column with words to theDataFrame. - The
HashingTF.transform()method converts the words column into feature vectors, adding a new column with those vectors to theDataFrame. - Now, since
LogisticRegressionis anEstimator, thePipelinefirst callsLogisticRegression.fit()to produce aLogisticRegressionModel. - If the
Pipelinehad moreEstimators, it would call theLogisticRegressionModel’stransform()method on theDataFramebefore passing theDataFrameto the next stage.
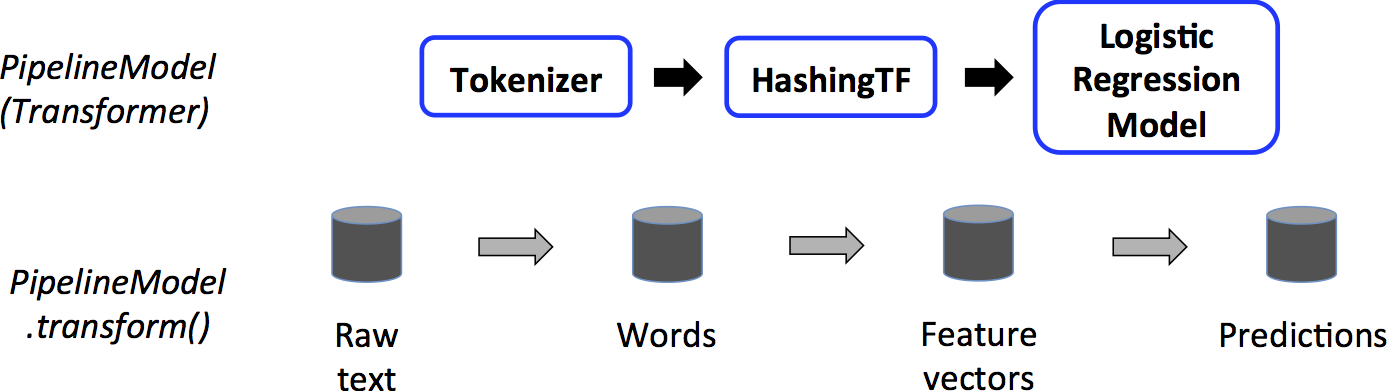
- A
Pipelineis anEstimator. Thus, after aPipeline’sfit()method runs, it produces aPipelineModel, which is aTransformer. ThisPipelineModelis used at test time; the figure below illustrates this usage. - In the figure above, the
PipelineModelhas the same number of stages as the originalPipeline, but allEstimators in the originalPipelinehave becomeTransformers. - When the
PipelineModel’stransform()method is called on a test dataset, the data are passed through the fitted pipeline in order. - Each stage’s
transform()method updates the dataset and passes it to the next stage. Pipelines andPipelineModels help to ensure that training and test data go through identical feature processing steps.
- The first two (
Reference
Apache Spark: the New ‘king’ of Big Data
http://vincentgaohj.github.io/Blog/2020/12/09/Apache-Spark-the-new-king-of-Big-Data/