AWS Solution Architect(Associate) - Topic 3: Database on AWS
Choose from 15 purpose-built database engines including relational, key-value, document, in-memory, graph, time series, and ledger databases.
With AWS databases, you don’t need to worry about database management tasks such as server provisioning, patching, setup, configuration, backups, or recovery.

[toc]
Database on AWS
Overview
Database Types
- RDS (OLTP): SQL Server; Oracle; MySQL Server; PostgreSQL; Aurora: MariaDB. RDS has two key feature: Multi-AZ - For Disaster Recovery; Read Replicas - For performance.
- DynamoDB (NoSQL)
- Red Shift OLAP

OLTP vs OLAP
- Online Transaction Processing (OLTP) differs from Online Analytics Processing (OLAP) in terms of the types of queries you will run.
**Redshift for Data Warehousing **
- Used for business intelligence. Tools like Congnos, Jaspersoft, SQL Server Reporting Services, Oracle Hyperion, SAP NetWeaver.
- Used to pull in very large and complex data sets. Usually used by management to do queries on data (such as current performance vs targets etc)
- Data Warehousing databases use different type of architecture both from a database perspective and infrastructure layer. Amazon’s Data Warehouse Solution is Called Redshift.
ElastiCache
- ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud.
- Used to speed up performance of existing databases (frequent identical queries).
- ElastiCache supports two open-source in-memory caching engines:
- Memcached
- Redis
Remember the following points:
- RDS runs on virtual machines
- You cannot log into these operating systems however
- Patching of the RDS Operating System and DB is Amazon’s responsibility
- RDS is NOT Serverless
- Aurora Serverless IS Serverless
RDS - Back Ups, Multi-AZ & Read Replicas
Back Ups
Automated Backups
- Automated Backups allow you to recover your database to any point in time within a “retention period”. The retention period can be between one and 35 days.
- Automated Backups will take a full daily snapshot and will also store transaction logs throughout the day.
- When you do a recovery, AWS will first choose the most recent daily back up, and then apply transaction logs relevant to that day. This allows you to do a point in time recovery down to a second, within the retention period.
- Enabled by default.
- The backup data is stored in S3 and you get free storage space equal to the size of your database.
- Backups are taken within a defined window. During the backup window, storage I/O may be suspended while your data is being backed up.
Database Snapshots
- DB Snapshots are done manually.
- They are stored even after you delete the origin RDS instance, unlike automated bakeups.
Restoring Backups
- Whenever you restore wither an Automatic Backup or a manual Snapshot, the restored version of the database will be a new RDS instance with a new DNS (Domain Name System) endpoint.
Encryption At Rest
- Encryption is done using the AWS KMS (Key Management Service).
- Once your RDS instance is encrypted, the data stored at rest in the underlying storage is encrypted, as are its automated backups, read replicas, and snapshot.
- Encryption is available for all six of the engines (MySQL, etc.)
Multi-AZ
- Multi-AZ allows you to have an exact copy of your production database in another Availability Zone.
- AWS handles the replication for you, so when you production database is written to, this write will automatically be synchronized to the stand by database.
- In the event of planned database maintenance, DB Instance failure, or an Availability Zone failure, Amazon RDS will automatically fail-over to the standby so that database operations can resume quickly without administrative intervention.
- Aurora is not involved in Multi-AZ, because Aurora by its own architecture is completely fault tolerant.
- Used for DR (Disaster Recovery)
Read Replica
- Read replicas allow you to have a read-only copy of your production database.
- This is achieved by using Asynchronous replication from the primary RDS instance to the read replica. You use read replicas primarily for very read-heavy database workloads.
- SQL Server is not available for the read replicas.
- Used for scaling, not for DR (Disaster Recovery)!
- Must have automatic backups turned on
- Each read replica will have its own DNS end point
- You can have read replicas that have Multi-AZ
- You can create read replicas of Multi-AZ source databases
- Read replicas can be promoted to be their own databases. This breaks the replications. So if you do promote a read replica to be its own independent database the replication will no longer work.
- You can have a read replica in a second region.
DynamoDB
FYI: I highly recommend you to watch it, it is mind-blowing.
Basic DynamoDB
Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. It is a fully managed database and supports both document and key-value data models. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad-tech, IoT, and many other applications.
The Basics of DynamoDB
- Stored on SSD storage
- Spread across 3 geographically distinct data centers
- Eventual Consistent Reads (Default): Consistency across all copies of data is usually reached within a second.
- Strongly Consistent Reads: Return a result that reflects all writes that received a successful response prior to the read.
Tenets of NoSQL DATA MODELING
- Understand the use case
- Define the access patterns
- Read/Write workloads
- Data-modeling
- Avoid relational design patterns, use one table
- 1 application service = 1 table
- Reduce round trips
- Simplify access patterns
- Identify Primary Keys
- How will items be inserted and read?
- Overload items into partitions
- Define indexes for secondary access patterns
Advanced DynamoDB
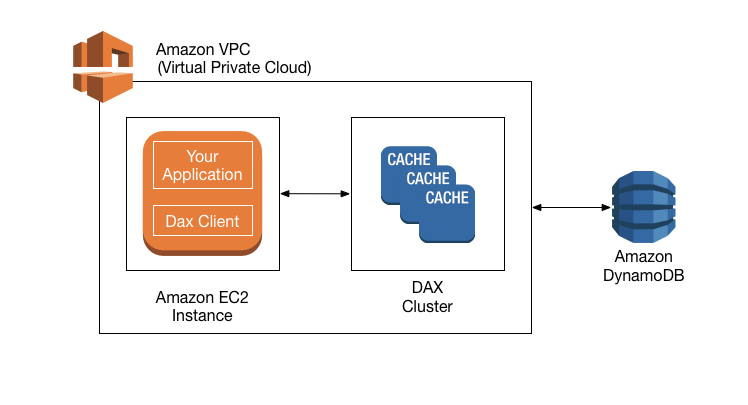
- Fully managed, highly available, in-memory cache
- 10x performance improvement
- Reduces request time from milliseconds to microseconds – even under load.
- No need for developers to manage caching logic
- DAX is completely compatible with DynamoDB API calls
- Multiple “all-or-nothing” operations
- Financial transactions / Fulfilling orders
- Two underlying reads or writes – prepare/commit
- Up to 25 items or 4 MB of Data
On-Demand Capacity
- Pay-per-request pricing
- Balance cost and performance
- No minimum capacity
- No charge for read/write – only storage and backups
- Pay more per request than with provisioned capacity
- Use for new product launches
- Full backups at any time
- Zero impact on table performance or available
- Consistent within seconds and retained until deleted
- operates within same region as the source table
- Protects against accidental writes or deletes
- Restore to any point in the past 35 days
- Incremental backups
- Not enabled by default
- Latest restorable: five minutes in the past
Streams
- Time-ordered sequence of item-level changes in a table
- Stored for 24 hours
- Inserts, updates, and deletes
Managed Multi-Master, Multi-Region Replication
- Globally distributed applications
- Based on DynamoDB streams
- Multi-region redundancy for DR (Disaster Recovery) or HA (High Availability)
- No need to rewrite the application, DynamoDB handle it automatically for you
- Replication latency under one second
Database Migration Service (DMS)
At a high level, when using AWS DMS you do the following:
- Create a replication server.
- Create source and target endpoints that have connection information about your data stores.
- Create one or more migration tasks to migrate data between the source and target data stores.
A task can consist of three major phases:
- The full load of existing data
- The application of cached changes
- Ongoing replication
Security
- Encryption at rest using KMS
- Site-to-site VPN
- Direct Connect (DX)
- IAM policies and roles
- Fine-grained access: This is where you have an IAM policies that allows users access to only certain attributes within DynamoDB table items.
- CloudWatch and CloudTrail
- VPC endpoints: For DynamoDB to enable EC2 instances in your VPC to use their private IP addresses to access DynamoDB with no exposure to the public Internet.
Redshift
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools. It is optimized for datasets ranging from a few hundred gigabytes to a petabyte or more and costs less than $1,000 per terabyte per year, a tenth the cost of most traditional data warehousing solutions.

Redshift can be configured as follows
- Single Node (160 GB)
- Multi-Node
- Leader Node (manages client connections and receives queries.)
- Compute Node (store data and perform queries and computations). Up to 128 Compute Nodes.
Advanced Compression
Amazon Redshift employs multiple compression techniques and can often achieve significant compression relative to traditional data stores.
Massively Parallel Processing (MPP)
- Amazon Redshift automatically distributes data and query load across all nodes. Amazon Redshift makes it easy to add nodes to your data warehouse and enables you to maintain fast query performance as your data warehouse grows.
Redshift Backups
- Enabled by default with a 1 day retention period.
- Maximum retention period is 35 days.
- Redshift always attempts to maintain at least three copies of your data. (the original and replica on the compute nodes and a backup in Amazon S3)
- Redshift can also asynchronously replicate your snapshots to S3 in another region for disaster recovery.
Redshift is priced as follow
- Compute Node Hours. And you will not be charged for leader node hours, only compute nodes will incur charges.
- Backups
- Data transfer (only within a VPC, not outside it)
Security Considerations
- Encrypted in transit using SSL
- Encrypted at rest using AWS-256 encryption
- By default RedShift takes care of key managements.
- Manage your own keys through HSM
- AWS Key Management Service
Redshift Availability
- Currently only available in 1 AZ
- Can storage snapshots to new AZs in the event of an outage.
Exam Tips
- Redshift is used for business intelligence
Aurora
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database engine that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
Things to know about Aurora
- Start with 10 GB, Scales in 10 GB increments to 64 TB (Storage Autoscaling)
- Compute resources can scale up to 32vCPUs and 244 GB of Memory.
- 2 copies of your data is contained in each availability zone, with minimum of 3 availability zones. 6 copies of your data.
Three Types of Aurora Replicas are available
- Aurora Replicas (Currently up to 15)
- MySQL Read Replicas (Currently up to 5)
- PostgresQL Read Replicas (Currently up to 1)
What is Amazon Aurora Serverless
Provides a relatively simple. cost-effective option for infrequent, intermittent, or unpredictable workloads.
- An on-demand, autoscaling configuration for the MySQL-compatible and PostgreSQL-compatible editions of Amazon Aurora.
- An Aurora Serverless DB cluster automatically starts up, shuts down, and scales capacity up or down based on your application’s needs.
Exam Tips
- 2 copies of your data are contained in each availability zone, with minimum of 3 availability zones. 6 copies of your data.
- You can share Aurora Snapshots with other AWS accounts
- 3 types of replicas available. Aurora Replicas, MySQL replicas & PostgresQL replicas. Automated failover is only available with Aurora Replicas.
- Aurora has automates backups turned on by default. You can also take snapshots with Aurora. You can share these snapshots with other AWS accounts.
- Use Aurora Serverless if you want a simple, cost-effective option for infrequent, intermittent, or unpredictable workloads.
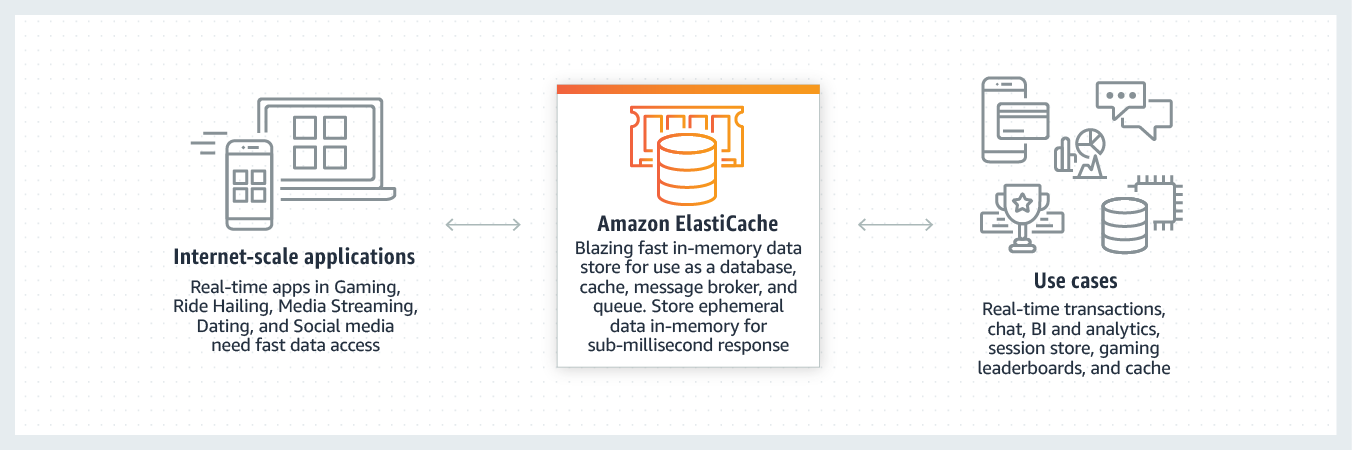
ElastiCache
ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud. The service improves the performance of web applications by allowing you to retrieve information from fast, managed, in-memory caches, instead of relying entirely on slower disk-cased databases. ElastiCache supports two open-source in-memory caching engines: Memcached and Redis.
Memcached
- Simple Cache to offload DB
- Scale horizontally
- multi-thread performance
Redis
- Advanced data types
- Ranking/Sorting data sets
- Pub/Sub capabilities
- Persistence
- Multi-AZ
- Backup & Restore Capabilities
Exam Tips
- Use ElastiCache to increase database and web application performance
- Redis is Multi-AZ
- You can do back ups and restores of Redis
Database Migration Service (DMS)
DMS is a cloud service that makes it easy to migrate relational databases, data warehouses, NoSQL databases, and other types of data stores. You can use AWS DMS to migrate your data into the AWS Cloud, between on-premises instances(through an AWS Cloud Setup), or between combinations of cloud and on-premises setups.

Exam Tips
- DMS allows you to migrate databases from one source to AWS
- The source can either be on-promises, or inside AWS itself or another cloud provider such as Azure.
- You can do homogeneous migrations(same DB engines) or heterogeneous migrations.
- If you do a heterogeneous migration, you will need the AWS Schema Conversion Tool (SCT).
Caching Services
Caching is a balancing act between up-to-date, accurate information and latency. We can use the following services to cache on AWS.
- CloudFront
- API Gateway
- ElastiCache – Memcached and Redis
- DynamoDB Accelerator (DAX)
EMR Overview
Amazon EMR makes it easy to set up, operate, and scale your big data environments by automating time-consuming tasks like provisioning capacity and tuning clusters.
Amazon EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. With EMR you can run petabyte-scale analysis at less than half of the cost of traditional on-premises solutions and over 3x faster than standard Apache Spark.
What is EMR?
- The central component of Amazon EMR is the cluster.
- A cluster is a collection of Amazon Elastic Compute Cloud (Amazon EC2) instances.
- Each instance in the cluster is called a node. Each node has a role within the cluster, referred to as the node type.
Exam Tips
- EMR is used for big data processing
- Consists of a master node, a core node, and (optionally) a task node.
- By default, log data is stored on the master node
- You can configure replication to S3 on five-minute intervals for all log data from the master node; however , this can only be configured when creating the cluster for the first time.
REMEMBER TO READ FAQ
AWS Solution Architect(Associate) - Topic 3: Database on AWS
http://vincentgaohj.github.io/Blog/2020/10/20/AWS-Solution-Architect-Associate-3-Database-on-AWS/