Convolutional Neural Networks
Attention
- 本文适合已经对向后传播(Backpropagation)神经网络有所了解的同学进一步学习卷积神经网络(CNN),感到困难的同学可以自行学习BP后再阅读。
- This article is suitable for students who are already familiar with Backpropagation Neural Networks to further study Convolutional Neural Networks (CNN). Students who find it difficult can learn BP on their own before reading.
Outline:
1.卷积(Convolution)
- 什么是卷积
- 卷积为什么能够提取text,image中的特征
- 在NLP中直观的理解卷积
- 卷积的意义
2.池化(Pooling)
- 什么是池化
- 几种池化的方法
- 池化的意义
卷积(Convolution)
什么是卷积
我们现在有$f(x)和g(x)$这两个函数,卷积是发生在这两个函数之间的计算。
卷积的数学定义如下:
连续定义:
$$
(f*g)(n)=\int_{-\infty}^{\infty}f(\tau)g(n-\tau)d\tau
$$
离散定义:
$$
(f * g)(n)=\sum_{\tau=_\infty}^{\infty}f(\tau)g(n-\tau)
$$
如果是低年级的同学(就像我)没有接触过卷积一定会很困扰,这个看起来很复杂的东西到底是什么?$n,\tau$有没有什么特别的意义?(实际上就是个符号,在没有情景时没有现实意义)。关于公式的来源这里不赘述,同学们也不必纠结(以后有些课程中会讲到)。我们定义出这个公式,是因为其在现实中有着广泛的应用,本文着重从现实意义解释卷积。
我们可以观察到求和时$f,g$的自变量取值是一个定值$\tau+(n-\tau)=n$($n$由我们想求解何处卷积而决定),这就是理解卷积的关键。卷积实在将两个函数相乘,再使他们的自变量和为常数后求积分。下面举几个例子。
信号处理
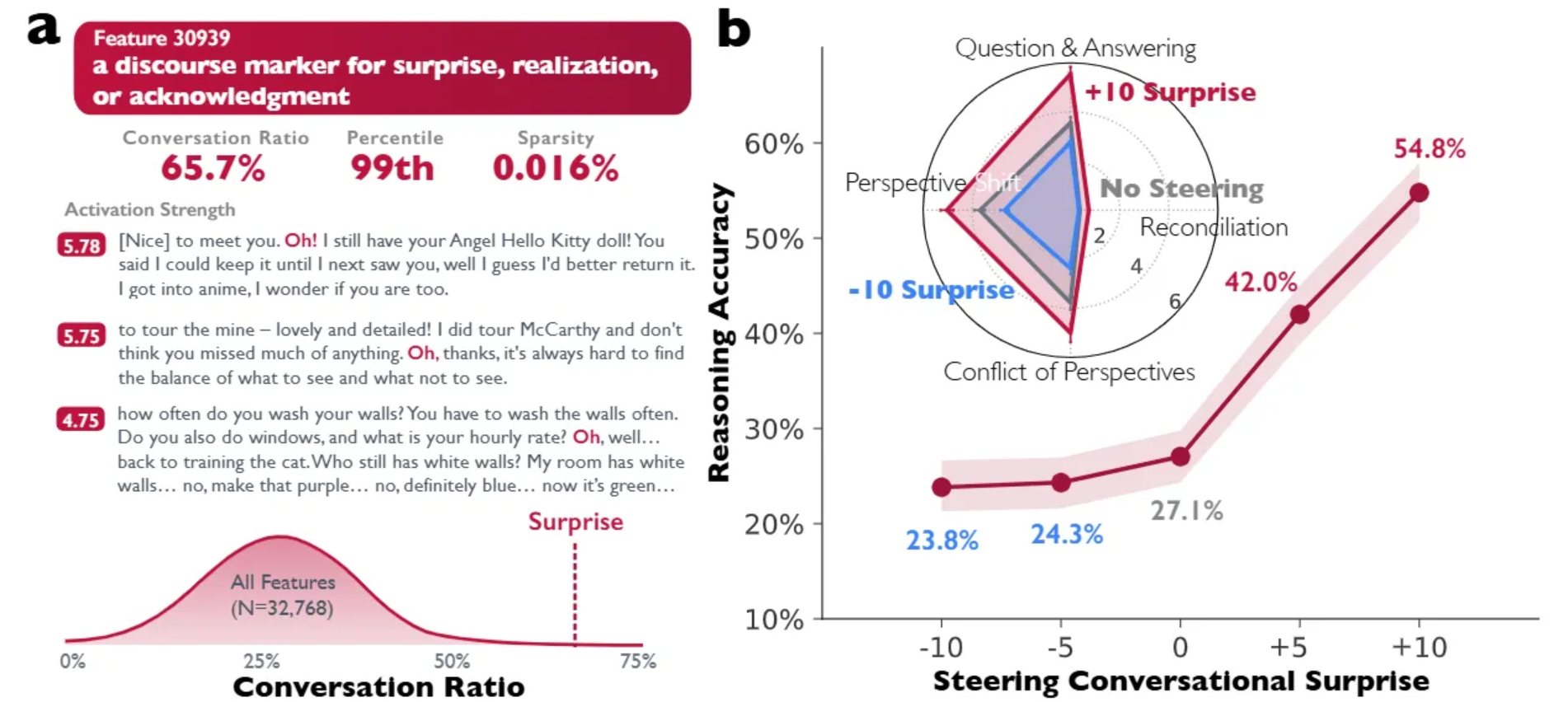
$f(t)$表示0-20时间内的离散信号输入,$g(t)$表示系统对一个输入信号响应随时间的衰减。在这个每隔一秒输入一个信号地系统,其某时刻地信号强度和之前输入地信号均有关(叠加的)。比如在$t=8$时,$t=0$输入的信号就衰减成$f(0)g(10)$其他的都以此类推,即此时的信号强度为:
$$
(f*g)(10)=\sum_{\tau=0}^{10}f(\tau)g(10-\tau)
$$
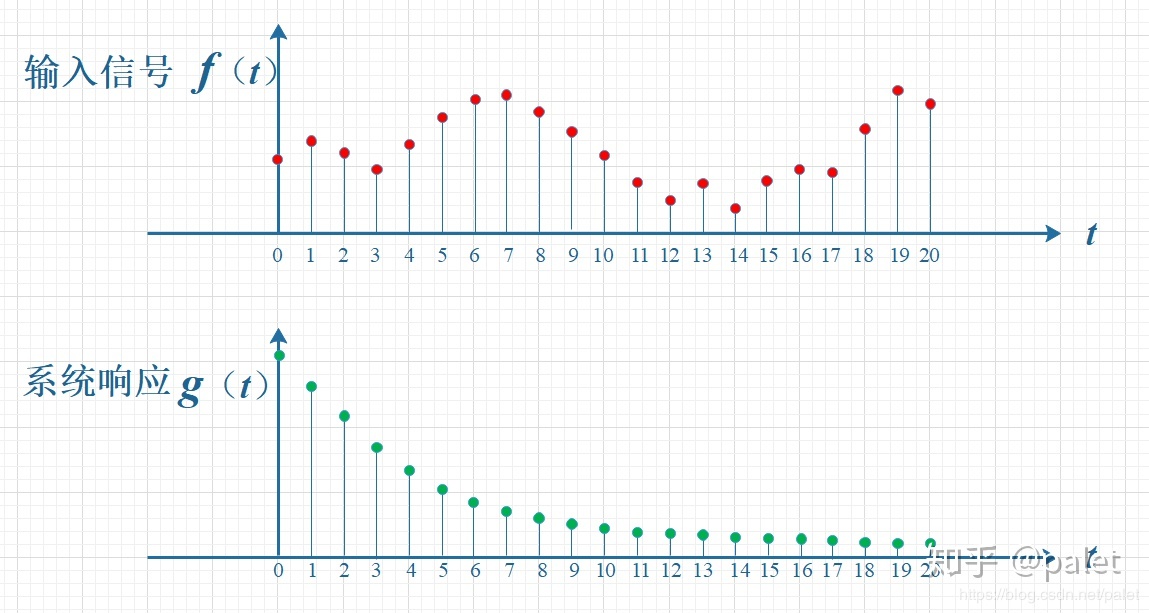
这正是上面所说的卷积,可以看出其在信号处理有这样的应用。如果我们把一个信号的衰减程度$g$看作它的权重,某一时刻的信号强度就可以看作之前输入信号的加权叠加。在这里我们可以说,卷积是一个函数以另一个函数为权重的加权叠加。(关于卷积还有另一种理解:将函数反转、反褶然后求和什么的,不是很直观,有兴趣的同学可以自行查看)。
至此我们说了两个关键点:
- **卷积是对两个数自变量和为常数的函数的积的求和(根本数学定义)。 **
- 卷积中一个函数可以看作另一个函数的权,卷积可以看作加权叠加(一种理解方式)。
带着这两个观点我们再看一个例子
掷骰子
同时掷两枚相同的骰子,求骰子的和为6的可能性。很明显骰子出现某个点数的概率是关于点数的常函数(函数值一直是1/6),这时两个函数自变量和为定值6,正是卷积发挥作用的场合。
概率为:
$$
(f*g)(6)=\sum_{\tau=1}^{5}f(\tau)g(6-\tau)
$$
下图为和的所有可能,均可用卷积计算。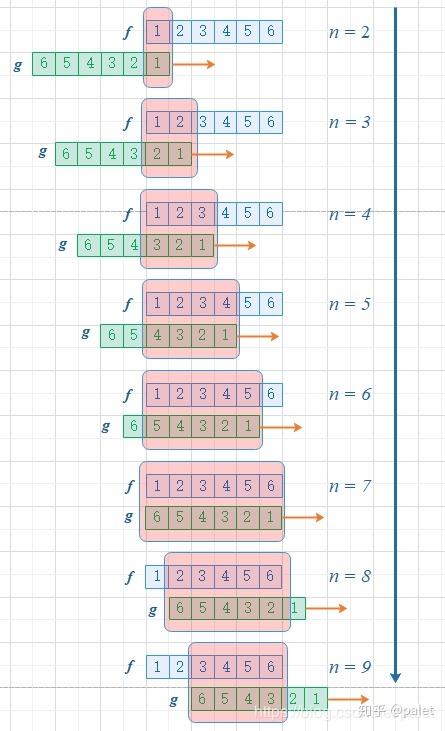
这个例子中把一个函数理解为另一个的权解释性并不好,所以关键的是理解数学定义后运用到合适的情境中。但在NLP和computer vision的领域中用加权叠加可以很好的解释卷积的作用。
卷积如何提取text,image特征
我们在 NLP 和 Computer Vision 中使用 CNN 是因为其能够提取 text ,image 中的特征,反映在出现特定特征时卷积会得到较大值(什么算较大值是规定好的)。这一机制具体如何实现请继续往下阅读,先在这里说明以免引起困惑。
NLP和Computer Vision中的卷积
NLP
一段文本作为词向量(非one-hot)输入神经网络,hidden-layer的神经元就会进行读取,CNN中正式以卷积操作来完成读取的。
几个重要的概念:
(统一写下,之后详解)
- filter过滤器、kernel卷积核、neuron神经元,实际上在CNN中指的都是神经网络的神经元。
- depth深度:一层卷积层(就是计算卷积的hidden-layer)有几个神经元depth就是几。
- size:表示为$n\times n$的形式,指的是receptive field-窗口的大小。
- stride步长:窗口一次移动的长度。
我们现在有这样一个text:“tentative deal reached to keep government open”并用如下的词向量表示(有四列常称有4个channels)。
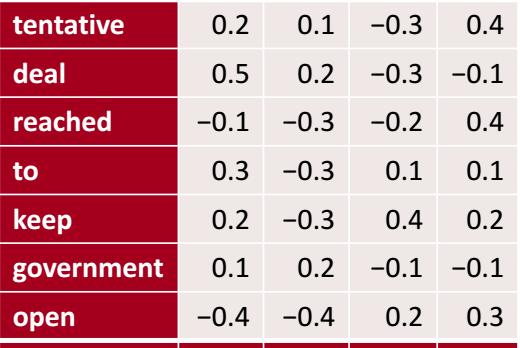
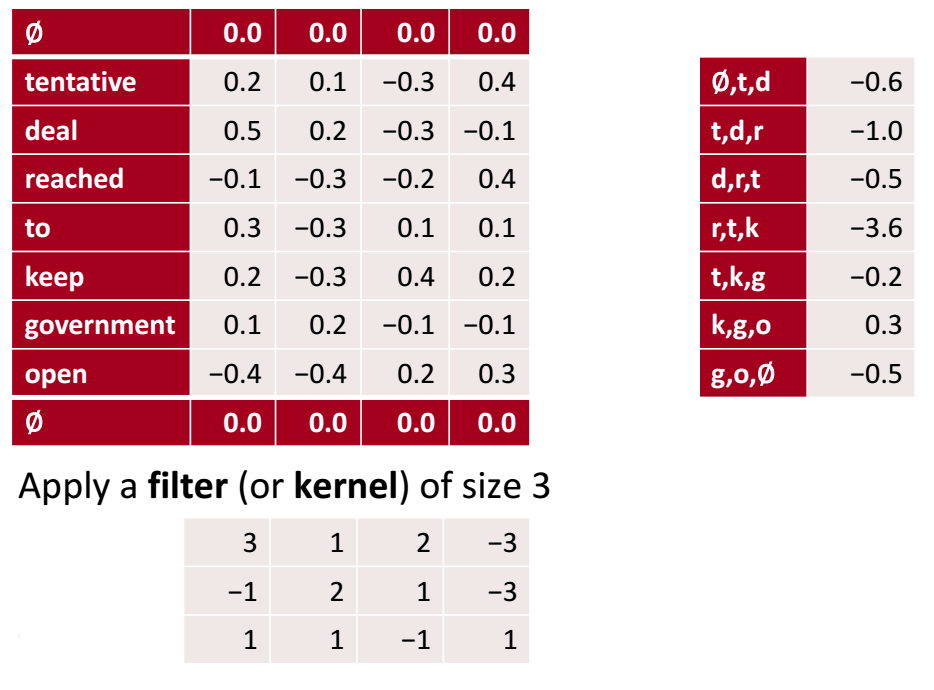
CNN的神经元用卷积来获取这样的text。紫色方框是刚刚提到的receptive field(窗口),size为$4\times4$. 在文本矩阵从上到下按照设置的stride(步长)移动窗口(设置1就每次移动一格,设置2就移动两格),每次得到的矩阵都用我们的filter\kernel(由训练得到,就是神经元中的参数)与其进行卷积运算**(矩阵中对应位置相乘再将所有位置的积相加,得到一个数就是卷积的结果),比如第一个窗口卷积为-1.0,第二个为-0.5.这样得到了右边只有一个channel的向量完成了文本的输入。把filter矩阵中的对应位置元素看作窗口中对应位置元素的权重,就符合加权叠加。**
这一步如何体现卷积的数学思想呢?
假设窗口中的矩阵为
$$
g=
\left[
\begin{matrix}
a_{1,1} & a_{1,2} & a_{1,3} & a_{1,3} \
a_{2,1} & a_{2,2} & a_{2,3} & a_{2,3} \
a_{3,1} & a_{3,2} & a_{3,3} & a_{3,3} \
\end{matrix}
\right]
$$
filter矩阵为:
$$
f=
\left[
\begin{matrix}
b_{1,1} & b_{1,2} & b_{1,3} & b_{1,3} \
b_{2,1} & b_{2,2} & b_{2,3} & b_{2,3} \
b_{3,1} & b_{3,2} & b_{3,3} & b_{3,3} \
\end{matrix}
\right]=\left[
\begin{matrix}
3 & 1& 2 & -3 \
-1 & 2 &1 & -3 \
1 & 1 & -1 & 1 \
\end{matrix}
\right]
$$
如果把我们的filter中心对称一下,
$$
f=
\left[
\begin{matrix}
b_{1,1} & b_{1,2} & b_{1,3} & b_{1,3} \
b_{2,1} & b_{2,2} & b_{2,3} & b_{2,3} \
b_{3,1} & b_{3,2} & b_{3,3} & b_{3,3} \
\end{matrix}
\right]=
\left[
\begin{matrix}
1 & -1 & 1 & 1 \
-3 & 1 & 2 & -1 \
-3 & 2 & 1 & 3 \
\end{matrix}
\right]
$$
现在想得到和刚刚相同权重分配效果,不能让对应位置相乘,等效计算应该是
$$
convolution=\sum_{n=1}^{3}a_{n,n}b_{4-n,4-n}
$$
完美的符合了卷积的数学定义**,自变量相加等于一个定值**$(4,4)$。这样我们就了解了卷积在NLP中的运作方式了。
但是得到的向量比原先的文本短,这并不是好的结果,我们希望得到长度相同的结果,方法如下图所示:
在输入的始末添加padding(填充层)在从上到下进行相同得分步骤就能得到和text(未添加padding之前)相同长度的结果了。
但是结果只有一个channel,表示一个feature,有点少了。这就是一个卷积层拥有多个神经元的作用,每个神经元都有一个filter\kernel(权重矩阵)来提取不同的特征:
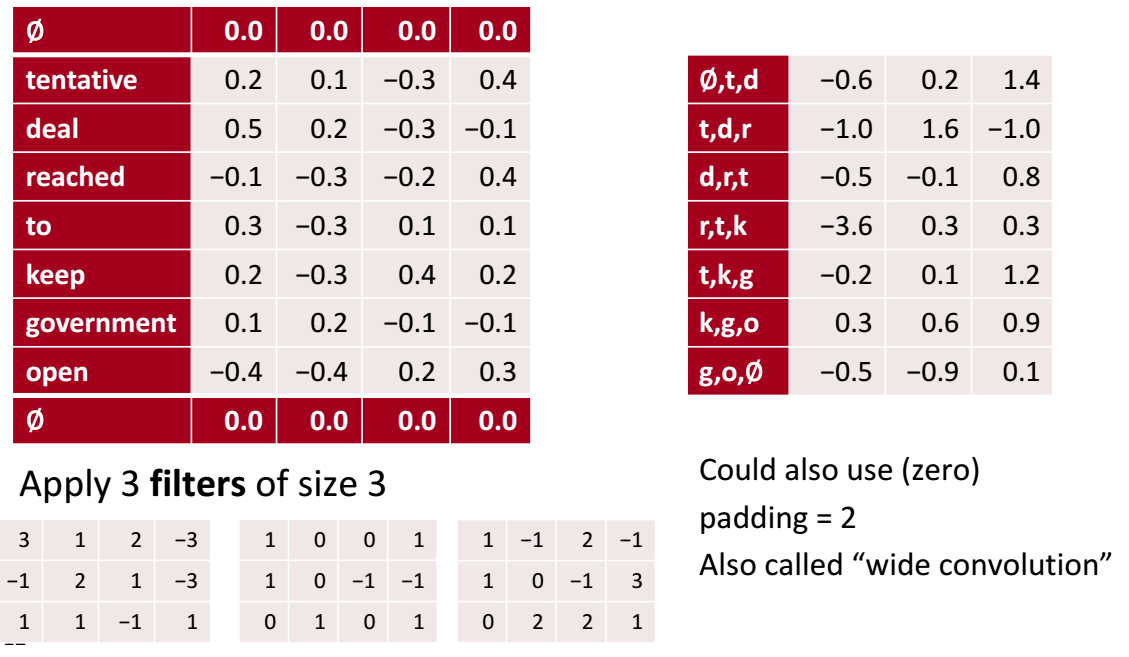
第一个filter可能专注于polite,这段文本是不是礼貌的,如果礼貌就应该得到较大值;第二个可能是关于food,如果出现食物相关的应该得到较大值。至于得到较大值的原因, 那就是通过学习不断更新filter矩阵使其能够有这样的能力(Backpropagation)。
卷积的优势
为什么这样滑动receptive field计算卷积就能获取feature呢?我们有这样的前提:
许多feature不需要看整个文本只需要看其中的一部分即可;
比如,想知道有没有关于食物的phrase,只要你扫描的关于食物的部分,得到了较大的卷积值就ok,不需要整篇文章一起看.相同的feature可能会出现在text的不同位置,这样使用同一filter扫描不同位置就能得到;
比如,对于food整篇文章就能公用一组参数.忽略我们截取的部分的语言合理性;
Regardless of whether phrase is grammatical
Not very linguistically or cognitively plausible
使用卷积有这样的优势:
共享权重,使得参数大幅度减少,减轻计算压力;
一般的全连接神经网络不关心各个输入之间的相关性,CNN这样就考虑了局部的特性;
为什么要使用卷积来分配权重,直接给每个词向量的每一维设置权重就好了呀。这就是以往全连接神经网络的思想,但这样的参数量过于庞大。在上面的例子中如果使用全谅解神经网络需要$8\times4=32$个参数才能提取text的一个feature但是CNN只需要12个。如果文本增长全连接神经网络的参数量也会上升,但卷积神经网络矩阵中仍是12个参数。
正是因为这样的特性使得CNN在ML占有一席之地,特别实在图像处理领域,全连接神经网络将每一个像素都分别赋予权重使得GPU负担过重,而卷积很好的解决了这个问题。把一部分一部分像素一起考虑,对于一个feature只使用一组参数,大大减少了图像识别的压力。比如我想知道这张图有没有手机,只需要对手机图像训练一组权重再对图像一部分一部分求卷积即可。
池化(Pooling)
什么是池化
相比卷积来说池化是一个比较简单的概念,其核心思想在于突出卷积计算的结果中重要的信息。
池化方法
Max pooling
取我们计算得到的矩阵每个channel的最大值,这样我们就能知道这段text是否含有我们想要的内容:如果第一行最大值足够大可能文本就是礼貌的。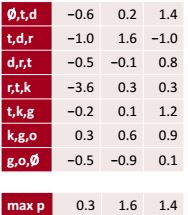
Average Pooling
用每一个channel的平均值,这样我们就知道这段text在什么程度上是polite。
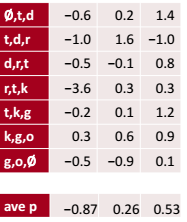
二者相比较大多数情况下MAX效果会好一些。因为text中feature的某些标志是稀少的,比如用了几个敬语就可以使一段话看起来礼貌;同时大多数的词和礼貌并无关系,比如and, or ,however。
Local-max Pooling
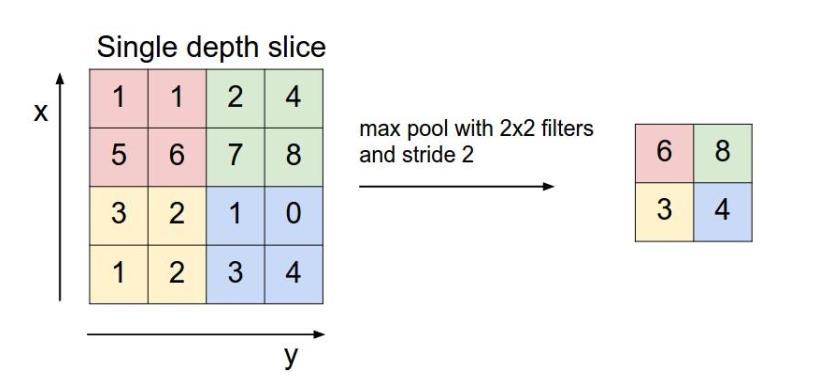
在图像处理中常用的方法,即选定一些区域,用这些区域的最大值来表示这些区域。作用为在保留主要特征的前提下压缩图片,减少数据和参数的量。
Convolutional Neural Networks
http://vincentgaohj.github.io/Blog/2019/04/30/Convolutional-Neural-Networks/