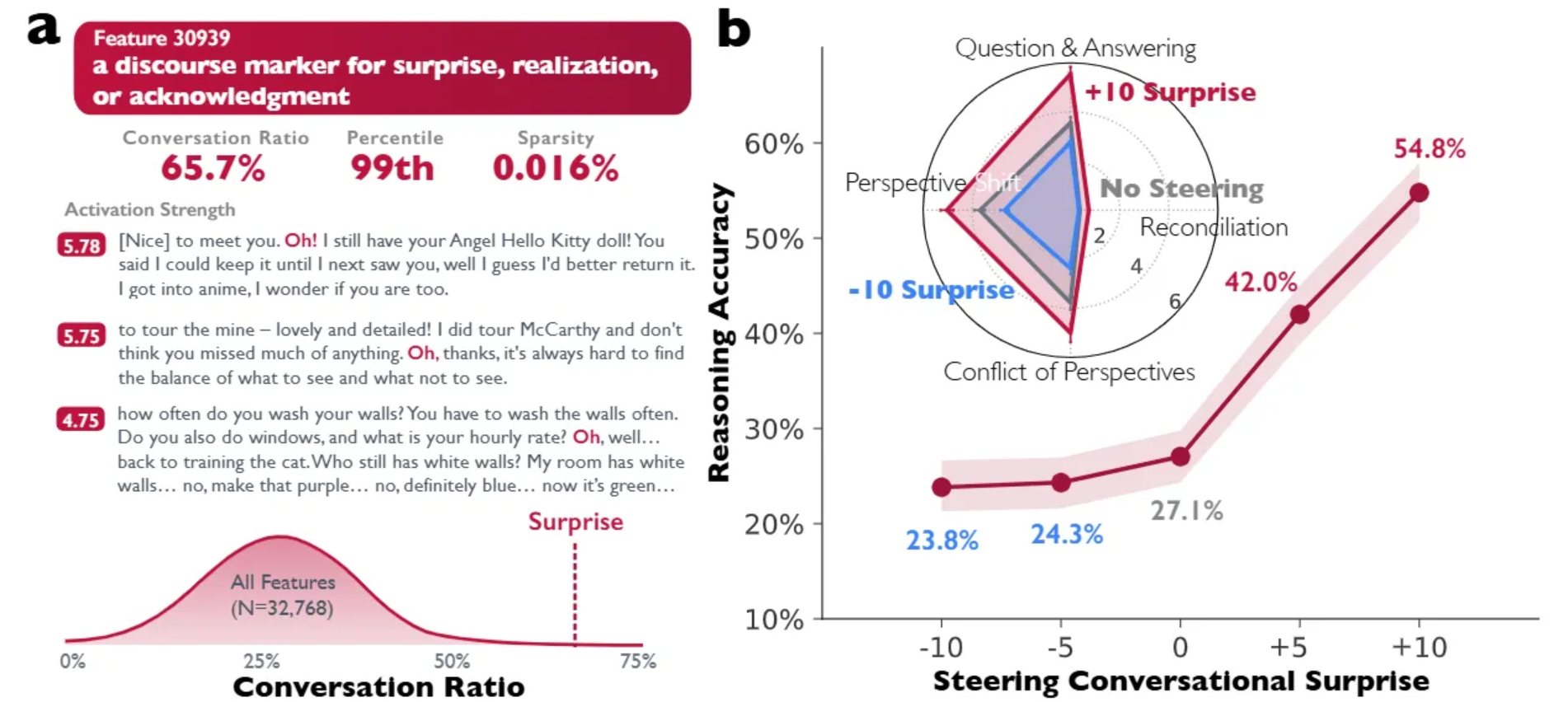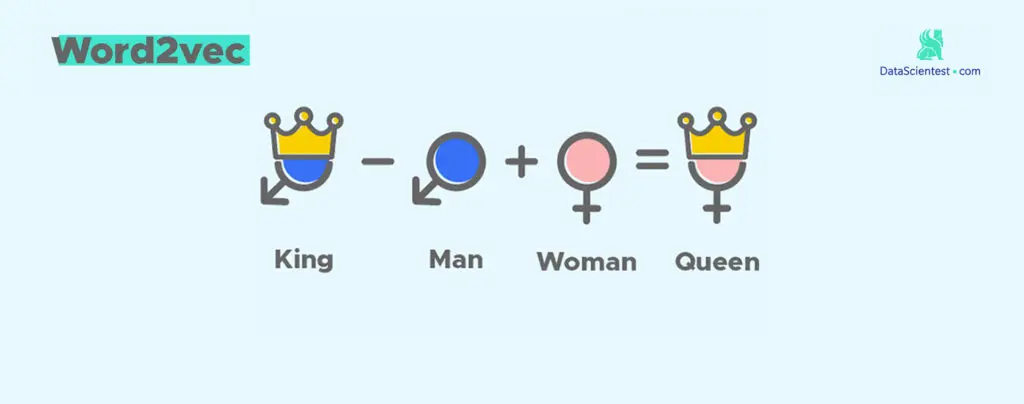
Insight into Word2Vec
A comprehensive understanding of Word2Vec, including background, development, and formula derivation
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理的最最基础的部分就是要让计算机能够识别人类的语言,因此词向量也就应运而生了。词向量顾名思义就是以向量的形式表示词。
几种常见的模型(由简单到复杂)
词袋模型
词袋模型的基本思想就是将文档中出现的所有词用一个袋子装起来。词袋模型不考虑词出现的先后顺序,并且认为文本中每个词出现的概率都是独立的,不依靠其他词的出现。
词袋模型可以看成是用向量来表示句子。即
| 词1 | 词2 | …… | 词n | |
|---|---|---|---|---|
| 句子1 | ||||
| 句子2 | ||||
| …… | ||||
| 句子m |
纵坐标为选定的特征词(可以是文档中所有出现的词,也可以是选定的某一些词)。可以认为最初的空格里面全是0,当句子中出现了某个词就在相应的位置做加一的操作,最后得到的数字的组合就是相应的句子的向量。
one-hot编码
one-hot编码是词向量模型的一种体现。这种编码是将文档中出现的所有的词用一个1和N-1个0表示,N是文档中出现的单词的个数。
| 维度1 | 维度2 | …… | 维度n | |
|---|---|---|---|---|
| 词1 | 1 | 0 | 0 | 0 |
| 词2 | 0 | 1 | 0 | 0 |
| …… | ||||
| 词n | 0 | 0 | 0 | 1 |
one-hot编码的好处是可以很好地表示离散数据,每一个词都可以用向量的形式表示出来。且一定程度上起到了升维的作用。在回归,分类,聚类等机器学习的算法中,特征之间距离的计算或者相似度的计算是非常重要的,而我们常用的距离或者相似度的计算都是在欧式空间的相似度计算。使用one-hot编码将离散特征的取值数字化表示到了欧式空间,离散特征的某个取值就对应与欧式空间的某个点。将离散型特征使用one-hot编码,有时确实会让特征之间的距离计算更加合理。
而坏处也比较明显,one-hot是词袋模型的体现,因此有着词袋模型的固有缺点(即忽略掉了词出现的顺序和词的上下文之间的联系)。并且one-hot编码会产生一个较大的稀疏矩阵,在用one-hot编码得到的向量计算时,如果词的维度很大可能造成维灾难而无法计算。
统计语言模型
N-Gram 模型算是对上面词袋模型的补充吧。词袋模型认为文本中每个词出现的概率都是独立的,而这与我们的常规认知是不相符合的(不然完形填空该怎么做啊),而N-Gram 模型则认为可以通过计算概率的方法来获得上下文之间的关系,并且参考的上下文的词越多,预测的越准确。
词袋模型的基本思想是用概率来表示上下文之间的关系
一个经典的例子:假设我们有一个由n个词组成的句子
$$
\mathrm { s } = \left( w _ { 1 } , w _ { 2 } , w _ { 3 } , \ldots \ldots w _ { \mathrm { n } } \right)
$$
如何衡量它的概率呢?让我们假设,每一个单词$w_i$都要依赖于从第一个单词$w_i$到它之前一个单词$w_{i-1}$的影响:
$$
\begin{array} { c }
\begin{array} { c } { p ( s ) = p \left( w _ { 1 } , w _ { 2 } , w _ { 3 } , \ldots , w _ { n } \right) = p \left( w _ { 1 } \right) \cdot p \left( w _ { 2 } | w _ { 1 } \right) \cdot p \left( w _ { 3 } | w _ { 2 } , w _ { 1 } \right) \cdot \ldots } \ { \cdot p \left( w _ { n } | w _ { n - 1 } , w _ { n - 2 } , \ldots , w _ { 1 } \right) } \end{array}
\end{array}
$$
这样求一个句子出现的概率就变成了求若干个条件概率。但这样又会出现参数过多的问题。因此我们引入马尔科夫假设,即一个词出现的概率只与它之前若干个出现的单词有关。
假设一个词出现的概率只与它前面$n$个词出现的概率相关,N-Gram也就由此而来了。通常情况下$n$越大,得到的概率越准确但同时计算量也越大,因此$n$一般取2或者3。
N-Gram 思想
一个先导的知识就是贝叶斯公式,这里关于贝叶斯公式不做过多的描述:
$$
P(B|A) = \frac{P(A|B)P(B)}{P(A)}
$$
$$
P(B_i|A) = \frac{P(A|Bi)P(Bi)}{P(A)} \
= \frac{P(A|Bi)P(Bi)}{\sum_{j=1}^{n} P(B_j)P(A|B_j)}
$$
从理解的角度可以认为是:
$$
P(规律|现象) = \frac{P(现象|规律)P(规律)}{P(现象)}
$$
考虑$p(w_k|w_1^{k-1})$的近似计算,利用Bayes公式,有:
$$
p(w_k|w_1^{k-1}) = \frac{p(w_1^k)}{p(w_1^{k-1})}
$$
根据大数定理,我们可以近似表示:
$$
p(w_k|w_1^{k-1}) \approx \frac{Count(w_1^k)}{Count(w_1^{k-1})}
$$
举个简单的例子就是:
$$
p(“你”|“我爱”) \approx \frac{Count(“我爱你”)}{Count(“我爱”)}
$$
从上述公式能够看出,一个词出现的概率和它之前出现的所有词都相关,如果假定一个词出现的概率只与它前面的固定书目的词相关,这就是N-Gram模型的重要思想,其中的数学逻辑就是做了一个$N-1$阶的Markov假设,认为一个词出现的概率只与它前面的$N-1$个词相关,也就是:
$$
p(w_k|w_1^{k-1}) \approx \frac{p(w_1^k)}{p(w_{k-n+1}^{k-1})}
$$
利用大数定律:
$$
p(w_k|w_1^{k-1}) \approx \frac{Count(w_1^k)}{Count(w_{k-n+1}^{k-1})}
$$
举例:假如$N=2$
$$
p(w_k|w_1^{k-1}) \approx \frac{Count(w_{k-1},w_{k})}{Count(w_{k-1})}
$$
$$
p(“你”|“我爱”) \approx \frac{Count(“爱你”)}{Count(“爱”)}
$$
所以N-Gram模型其实一个计算一个句子出现概率的模型,当我们需要计算一个句子出现的概率时,只需要计算相关的概率参数,然后将他们连乘起来就好了。
那么,我们怎么利用这样的思想,用机器学习的方法将语言进行建模呢?方法就是将我们所考虑的问题建成一个模型,然后构造出一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数,然后利用这一组最优的参数进行预测。
对于统计语言模型,可以利用最大似然的概念,将目标函数设置为:
$$
\prod_{Corpus} p(w|Context(w))
$$
利用前文的n-gram思想,$Context(w)=w_{i-n+1}^{i-1}$
实际中,我们采用极大对数似然,将乘法转换为加法,那么目标函数则为:
$$
\sum_{Corpus} \log p(w|Context(w))
$$
目标就是最大化极大对数似然函数。
一种简单的思路来解决这个问题,就是建立一个关于$w$和它上下文$Context(w)$的函数:
$$
p(w|Context(w)) = F(w,Context(w),\theta)
$$
这样一来就不用每次都遍历数据库了,只需要训练模型得到参数集,之后使用参数集中的参数,那么输入唯一之后输出也就唯一了。
两个重要模型
词向量界中有两个很重要的模型:
- CBOW (Continuous Bag-of-Words Model)
- Skip-gram (Continuous Skip-gram Model)
Word2Vec 模型中,主要有 Skip-Gram 和 CBOW 两种模型,从直观上理解,Skip-Gram 是给定 input word 来预测上下文。而 CBOW 是给定上下文,来预测 input word。
Word2Vec 模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec 的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵 —— 后面我们将会看到这些权重在 Word2Vec 中实际上就是我们试图去学习的 “word vectors”。基于训练数据建模的过程,我们给它一个名字叫 “Fake Task”,意味着建模并不是我们最终的目的。

这两个模型是两个思想,基于这两个思想,Word2Vec给出了两个框架,一个利用了霍夫曼树(Hierarchical Softmax),一个利用了负采样(Negative Sampling)。
CBOW模型的目标函数为:
$$
\sum_{w \in Corpus} \log p(w|Context(w))
$$
Skip-gram模型的目标函数为:
$$
\sum_{w \in Corpus} \log p(Context(w)|w)
$$
模型详解
Skip-gram 模型讲解
Fake Task
训练模型的真正目的是获得模型基于训练数据学得的隐层权重。为了得到这些权重,我们首先要构建一个完整的神经网络作为我们的 “Fake Task”,后面再返回来看通过 “Fake Task” 我们如何间接地得到这些词向量。
下面的图中给出了一些我们的训练样本的例子。我们选定句子 “The quick brown fox jumps over lazy dog”,设定我们的窗口大小为 2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表 input word,方框内代表位于窗口内的单词。

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union “或者” Russia “要比”Sasquatch“被赋予更高的概率。
我们如何来表示这些单词呢?首先,我们都知道神经网络只能接受数值输入,我们不可能把一个单词字符串作为输入,因此我们得想个办法来表示这些单词。最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行 one-hot 编码。
 隐层没有使用任何激活函数,但是输出层使用了 sotfmax。
隐层没有使用任何激活函数,但是输出层使用了 sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 (input word, output word) 这样的单词对,input word 和 output word 都是 one-hot 编码的向量。最终模型的输出是一个概率分布。
隐藏层部分
看下面的图片,左右两张图分别从不同角度代表了输入层 - 隐层的权重矩阵。左图中每一列代表一个 10000 维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。

所以我们最终的目标就是学习这个隐层的权重矩阵。
输出层部分
经过神经网络隐层的计算,ants 这个词会从一个 1 x 10000 的向量变成 1 x 300 的向量,再被输入到输出层。输出层是一个 Softmax 回归分类器(这部分会在后面稍微展开一些),它的每个结点将会输出一个 0-1 之间的值(概率),这些所有输出层神经元结点的概率之和为 1。
下面是一个例子,训练样本的计算示意图。
input word: “ants”
output word: “car”

模型理解
这部分官方已经给出了非常好的解释,这里就直接上英文原文吧:
Ok, are you ready for an exciting bit of insight into this network?
If two different words have very similar “contexts” (that is, what words are likely to appear around them), then our model needs to output very similar results for these two words. And one way for the network to output similar context predictions for these two words is if the word vectors are similar. So, if two words have similar contexts, then our network is motivated to learn similar word vectors for these two words! Ta da!
And what does it mean for two words to have similar contexts? I think you could expect that synonyms like “intelligent” and “smart” would have very similar contexts. Or that words that are related, like “engine” and “transmission”, would probably have similar contexts as well.
This can also handle stemming for you – the network will likely learn similar word vectors for the words “ant” and “ants” because these should have similar contexts.
Softmax 详解
在机器学习尤其是深度学习中,softmax 是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。他把一些输入映射为 0-1 之间的实数,并且归一化保证和为 1,因此多分类的概率之和也刚好为 1。
网上有一张图很好的说明了softmax的计算方法:

假设有一个数组 $V$,$V_i$表示 $V$ 中的第$ i $个元素,那么这个元素的 softmax 值为:
$$
S_i = \frac{e^i}{\sum_j e^j}
$$
该元素的 softmax 值,就是该元素的指数与所有元素指数和的比值。
模型公式推导
这里给出了几个模型的公式推导:
- 神经网络模型(One-Word模型)
- CBOW 模型
- Skip-gram 模型
One-Word 模型
One-Word 是用神经网络来实现 N-Gram($n=2$时)。即N-Gram是思想,而One-Word模型是实现方法。即一个用one-hot编码的词作为输入,通过第一个权重矩阵得到隐藏层,再通过第二个权重矩阵的到输出层的前身,该前身再做Softmax得到输出端的向量表示。

设:词汇量的大小为$V$,隐藏层的大小为$N$。输入向量是一个one-hot编码的向量,one-hot编码的向量表示为$(x_1,x_2,…,x_v)$,其中只有一个$x_k$为1,其余的均为0。姑且认为$X(V \times 1), h(N \times 1), Y(V \times 1)$都是列向量
输入层和隐藏层之间是一个$V \times N$的矩阵$W_{V \times N}$
$$
\left( \begin{array}{cccc}{\mathrm{W}{11}} & {\mathrm{W}{12}} & {\dots} & {\mathrm{W}{1 n}} \ {\mathrm{W}{21}} & {\mathrm{W}{22}} & {\dots} & {\mathrm{W}{2 n}} \ {\cdots} & {\cdots} & {\cdots} & {\cdots} \ {\mathrm{W}{\mathrm{vl}}} & {\mathrm{W}{\mathrm{v} 2}} & {\dots} & {\mathrm{W}_{\mathrm{vn}}}\end{array}\right)
$$
$$
h=x^T W
$$
则$h$为
$$
\left( \begin{array}{llll}{\mathrm{W}{\mathrm{kl}}} & {\mathrm{W}{\mathrm{k} 2}} & {\dots} & {\mathrm{W}_{\mathrm{kn}}}\end{array}\right)^{\mathrm{T}}
$$
即$W$矩阵的第$k$行的转置 (因为$x_k$为1,其余的均为0)
隐藏层到输出层是一个$N \times V$的权重矩阵
形式和上面那个矩阵类似,只是矩阵的元素用$\mathrm{w}_{\mathrm{ij}}^{\prime}$表示
$$
\mathrm{U}{\mathrm{j}}=\mathrm{W}{\mathrm{j}}^{\prime} \mathrm{h}
$$
注:$\mathrm{W}_{j}^{‘}$为$W$矩阵的第$j$行,$U_j$为输出层的第$j$个位置的前身
$U_j$经过一个Softmax回归得到$y_j$,$y_j$为正经的输出层的第$j$个位置
$$
\mathrm{P}\left(\mathrm{w}{j} | \mathrm{w}{I}\right)=y_{j}=\frac{e^{j}}{\sum_{i=1}^{V} e^{i}}
$$
即在输入已经确定的情况下,输出的值为$w_j$的概率为这个
更新$W$和$W^{‘}$矩阵
首先定义一个损失函数(我们希望这个损失函数最小)(至于为什么这么定义还是没太理解)
$$
\mathrm{E}=-\mathrm{P}\left(\mathrm{w}{\mathrm{o}} | \mathrm{w}{\mathrm{i}}\right)=\mathrm{U}{\mathrm{j}^{*}}-\log \left(\sum{i=1}^{V} e^{i}\right)
$$
首先更新$W^{‘}$矩阵:
这就需要用$E$来对$\mathrm{w}^{‘}_{\mathrm{ij}}$来求偏导,以获得最快更新$W^{‘}$的方向(即梯度方向)
在求偏导之前需要知道这样的前提 即
$$
\frac{\partial \mathrm{E}}{\partial \mathrm{U}{i}}=\mathrm{y}{\mathrm{i}}-\mathrm{t}_{\mathrm{i}}
$$
当预测准确的时候$t_i$为1,否则为0,这个计算公式可以看成是输出层的的预测误差,至于结果为什么是这样的暂时还不是很清楚
在上述前提下
$$
\frac{\partial \mathrm{E}}{\partial \mathrm{W}{\mathrm{ij}}}=\frac{\partial \mathrm{E}}{\partial \mathrm{U}{\mathrm{i}}} * \frac{\partial \mathrm{U}{\mathrm{i}}}{\partial \mathrm{w}{\mathrm{ij}}}=\left(y_{i}-t_{i}\right) * h_{i}
$$
则权重更新方程为
$$
\mathbf{W}{i j}^{\prime}=\mathbf{W}{i j}^{\prime}-\eta\left(y_{i}-t_{i}\right) * h_{i}
$$
其次更新$W$矩阵
和上文差不多,也是需要$W$对$\mathrm{W}_{\mathrm{ij}}$求偏导
求之前也需要知道一个前提:
$$
\frac{\partial \mathrm{E}}{\partial h_{i}}=\sum_{i=1}^{V} \frac{\partial \mathrm{E}}{\partial U_{i}} \frac{\partial U_{i}}{\partial h_{i}}=\sum_{i=1}^{V}\left(y_{i}-t_{i}\right) * w_{i j}^{\prime}
$$
此式子的结果用$\mathrm{EH}_{\mathrm{i}}$代为表示:
$$
\mathrm{EH}=\left(\mathrm{EH}{1} \cdot \mathrm{EH}{2}, \ldots . . \mathrm{EH}_{\mathrm{N}}\right)
$$
在此前提下求$E$对$\mathrm{W}{i j}$的偏导数为:
$$
\frac{\partial \mathrm{E}}{\partial \mathrm{w}{i j}}=\frac{\partial \mathrm{E}}{\partial \mathrm{h}{j}} \frac{\partial \mathrm{h}{j}}{\partial \mathrm{w}{i j}}=E H{j} * X_{i}
$$
由于X非1即0,所以权重更新公式为:
$$
\mathrm{V}{w i}=\mathrm{V}{w i}-\eta E H
$$
其中$\mathbf{V}_{w i}$为one-hot编码中非零行所对应的矩阵的行,其他行不用关心。
CBOW 模型(连续词袋模型)
- 基本概念
CBOW 的基本思想是用中心词的上下文的c个词来预测中心词。
连续词袋模型模型相当于是 One-Word 模型的补充,One-Word 是一个输入,一个输出,CBOW 是 c 个输入,1个输出。

- $\mathrm{X}_{mathrm{1}, mathrm{k}}$ 是上下文第 1 个单词的 one-hot 编码。
- $\mathrm{X}_{mathrm{c}, mathrm{k}}$ 是第 C 个单词的 one-hot 编码。
- 这C个 one-hot 编码通过相应位置加和求平均的方法得到一个$1 \times \mathrm{V}$ 的向量。
该向量再乘以我们期望得到的第一个矩阵$\mathrm{W}{\mathrm{V} \times \mathrm{N}}$来得到隐藏层的向量$h_i$,一个$1 \times N$的向量),即
$$
\mathrm{h}=\frac{1}{C} W\left(\sum{i=1}^{C} x_{i}\right)
$$
上图的$h_i$表示的意思可以与上上图的$h_i$相比较。然后$h$乘以另一个我们期望得到的矩阵:
$$
\mathrm{W}_{\mathrm{N}^{‘} \mathrm{V}}^{*}
$$
得到一个$1 \times \mathrm{V}$的向量U,再用Softmax得到一个$1 \times \mathrm{V}$的向量$Y$,其中$Y_i$最大的那个值就是期待的中心词。通过不断地学习来调整 $\mathrm{W}$ 和 $\mathrm{W}^{‘}$ 的值。
- CBOW矩阵的调整
建立一个损失函数:
$$
\mathrm{E}=-\log \left(\mathrm{P}\left(\mathrm{w}{\mathrm{o}} | \mathrm{W}{\mathrm{I}, 1} \ldots \mathrm{W}{\mathrm{I}, \mathrm{c}}\right)\right)\
=-U{j^{*}}+\log \left(\sum_{j}^{V} e^{u_{i}}\right)\
=-\mathrm{V}{\mathrm{w}{\mathrm{o}}}^{\prime T} \cdot h+\log \left(\sum_{i=1}^{V} e^{v_{v_{i}} T} \cdot h\right)
$$
然后和上面one-word模型更新两个矩阵的方法类似 都是对相应的矩阵的元素求导得到梯度来更新矩阵。
$$
\mathrm{V}{\mathrm{wj}}^{\prime}=\mathrm{V}{\mathrm{wj}}^{\prime}-\eta\left(\mathrm{y}{\mathrm{i}}-\mathrm{t}{\mathrm{i}}\right) \mathrm{h}
$$
用上述公式来更新$W^{‘}$,其中$j=1,2, \dots \dots ,\mathrm{V}$
其中$\mathrm{V}^{\prime}_{\mathrm{w} j}$为隐藏层到输出等的矩阵的第$j$列
$$
\mathrm{V}{\mathrm{w}, \mathrm{I}, \mathrm{c}}=\mathrm{V}{\mathrm{w}, \mathrm{I}, \mathrm{c}}-\frac{1}{\mathrm{C}} \eta \cdot \mathrm{EH}
$$
用上述公式来更新$W$
其中$\mathrm{V}_{\mathrm{w}, \mathrm{I}, \mathrm{c}}$是输入上下文单词的第c个单词的输入向量。其中$c=1,2, \cdots \cdots ,\mathrm{C}$。
Skip Gram 模型
模型概述
Skip-Gram 模型可以看成是与 CBOW 模型相反的,即用一个中心词来推测其附近的 c 个上下文(注:得到的 c 个上下文不考虑与中心词之间的距离的影响)。

数学推导
隐藏层$h$仍然是矩阵$W$的第$k$行($X_k=1$的情况下)
与之前稍微有点不同的是Skip-Gram模型的输出有多个,每个输出都使用的相同的$W^{‘}$来计算
$$
\mathrm{P}\left(\mathrm{w}{c, j}=w{o, c} | w_{I}\right)=y_{c, j}=\frac{e^{u_{c, j}}}{\sum_{i=1}^{V} e^{u_{i}}}
$$
- 其中 $\mathrm{W}_{\mathrm{c}, \mathrm{j}}$ 是输出层第 $c$ 个输出的第 $j$ 个单词。
- 而 $\mathrm{w}_{\mathrm{o}, \mathrm{f}}$ 是第c个输出的实际输出的单词。
- $\mathrm{U}_{\mathrm{c}, \mathrm{j}}$ 是 h 与 $\mathrm{W}^{‘}$ 的第 $j$ 行向量相乘的结果,由于乘的都是同一个第 $j$行。
所以:
$$
\mathrm{U}{\mathrm{c}, \mathrm{j}}=\mathrm{U}{\mathrm{j}}=V_{w_{j}}^{\prime T} h
$$
再次构造损失函数:
$$
\mathrm{E}=-\log \left(\mathrm{P}\left(w_{0,1}, w_{0,2}, \ldots w_{0, \mathrm{C}} | w_{\mathrm{I}}\right)\right) \
=-\sum_{i=1}^{C} U_{j_{i}^{*}}+\operatorname{Clog}\left(\sum_{i=1}^{V} U_{i^{\prime}}\right) \
$$
$$
\frac{\partial \mathrm{E}}{\partial \mathrm{U}{c, j}}=y{c, j}-t_{c, j}
$$
用:
$$
\mathrm{EI}=\left{\mathrm{EI}{1}, \mathrm{EI}{2}, \ldots . \mathrm{EI}{\mathrm{v}}\right}
$$
来表示所有上下文单词的预测误差之和,即:
$$
\mathrm{EI}{\mathrm{j}}=\sum_{\mathrm{i}=1}^{\mathrm{C}} \mathrm{y}{\mathrm{i}, \mathrm{j}}-\mathrm{t}{\mathrm{i}, \mathrm{j}}
$$
$\mathrm{W}^{\prime}$的权重矩阵更新公式为:
$$
w_{i, j}^{\prime}=w_{i, j}^{\prime}-\eta^{} E I_{j}^{} h_{i}
$$
$V$的权重矩阵更新公式为:
$$
\mathrm{V}{\mathrm{w}{1}}=\mathrm{V}{\mathrm{w}{1}}-\eta \mathrm{EH}
$$
其中
$$
\mathrm{EH}=\sum_{j=1}^{V} E I_{j} * w_{i, j}^{\prime}
$$
参考来源
Insight into Word2Vec
http://vincentgaohj.github.io/Blog/2019/04/21/Insight-into-Word2Vec/